Fixing Failures in Browser-Use Models: Why More Data Isn't Enough
Yangyue Wang1, 2, Harshvardhan Sikka1, 2, Yash Mathur*2, Tony Zhou*2, Jinu Nyachhyon*2, Pranav Guruprasad1, 2
* Equal contributions. 1Fig; 2Manifold Research Group.
TL;DR
- We ran three LoRA fine-tuning experiments: varying perturbation type, data scale, and real vs. synthetic sources.
- Counter-intuitively, augmentation degrades performance rather than improving it. We find this points to issues in model representations and standard fine-tuning methodologies instead of the data itself
- We introduce the fine-tuned 7B GUI model trained on GUI-DR generated data to study the effects of synthetic data on the model's GUI grounding capability in supervised post-training.
GUI Perturbation — Research Series
Browser-Use & Computer Control Have Cognitive Behavior Gaps
The reflex for an unreliable computer-use agent (CUA) is to write a better prompt. Agent Skills, folders of instructions, scripts, and resources that an agent can discover and call, have made that approach both more capable and more popular [1]. The premise is reasonable: give the agent better instructions and it should behave better.
Prompting cannot supply a behavior the model never learned. Consider booking a flight. Without spatial-relation reasoning, the agent cannot tell whether seat 14A or 14C is the window seat. Without multi-region visual reading, it books May 21 instead of June 21 because it pulled the wrong cell from a dense calendar. Without instruction-ambiguity reasoning, it books the first flight in the list rather than asking which one you meant. Without self-reflection, it follows the wrong checkout flow all the way to the end. Without the ability to refute a premise, it loops forever hunting a menu item that no longer exists, or carries out a dangerous action because it was told to.
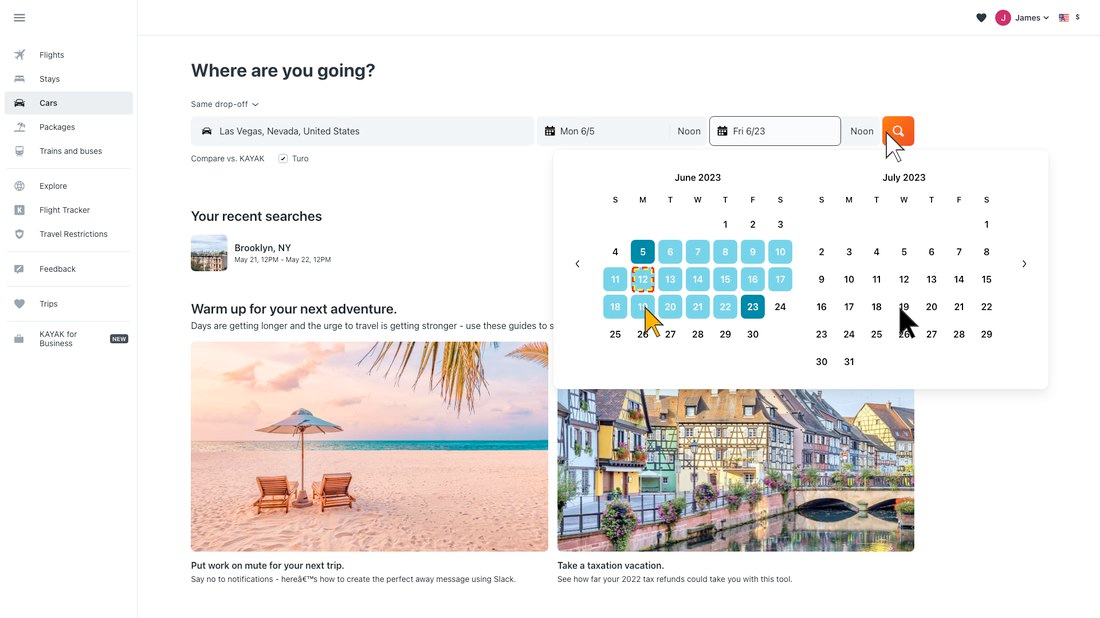
The limitations described above are training data problems, not prompting problems. A model picks up the behaviors needed to handle real software only when those behaviors appear in its training data. This post asks one question: can we train these behaviors into a model using GUI-Perturbed data? We find that the obvious approaches fail, and that the way they fail is the useful part.
Evaluation Gaps to Training Gaps
In Part 2 of this investigation, we found that state-of-the-art GUI models degrade sharply under two conditions: small visual perturbations, and instructions phrased as spatial relations. These models had seen millions of GUI screenshots, yet a change in zoom or a request for "the button above X" was enough to break them.
The cause is visible in how CUA training data is usually organized. Standard recipes sort data by surface category: platform, action type, application, UI element type [3-5, 7], and try to maximize diversity along those axes. The gaps Part 2 exposed do not lie on those axes. They are gaps in cognitive behavioral coverage: spatial reasoning, instruction disambiguation, invariance to visual appearance. A dataset can be exhaustive across platforms and applications and still contain almost no examples that demand reasoning about where one element sits relative to another.
Figure 2: Failure modes identified in part 2 vs. training interventions
That points to a direct test: If the gaps are behavioral, can we build training data that targets the missing behaviors and fills them?
As a first step, we study how synthetic grounding data, generated to exercise exactly these behaviors, affects a state-of-the-art model.
Why GUI Training Data is Hard to Get Right
Collection is Expensive & Synthesis is Fragile
There are two ways to get more grounding data, and each has a characteristic failure mode.
- Real trajectories are expensive. Collecting real interaction traces at scale is costly. OpenCUA [6] and the UI-TARS [2] pipeline show what is achievable, but the cost per trajectory stays high and the datasets stay narrow in behavioral diversity.
- Synthetic data is fragile. Generating data synthetically is the obvious alternative, and it brings its own risk. The Jedi dataset is the cautionary case: synthetic trajectories can look plausible while encoding shortcuts and rendering artifacts that do not transfer to real use, which is why a usable training mix still needs a large fraction of real screenshots [7].
| Synthetic Element | Synthetic Icon |
|---|---|
 |
 |
Figure 3: Jedi dataset examples. Click on each image to enlarge.
The result is that practitioners reach for whatever data is available and hope scale compensates for any distribution mismatch. The experiments below test whether that bet pays off.
LoRA as the Practical Post-Training Tool
Full fine-tuning is impractical at 7B+ parameters, so most teams reach for LoRA (low-rank adaptation): it is fast, memory-efficient, and easy to iterate on [8]. LoRA freezes the base weights and learns a small low-rank update on top, and that low-rank constraint is the catch. The rank sets a ceiling on how much representational change the update can express [9], and GUI spatial reasoning may demand exactly the deep visual-spatial realignment a low-rank update cannot reach.
The DoRA [10], GLAD [11], and EvoCUA [12] results all point the same way: LoRA fine-tuning of vision-language models (VLMs) can degrade capabilities in ways that are hard to predict in advance.
"Agentic Cognitive Behaviors"
By an agentic cognitive behavior we mean something specific: not an action type (click, scroll, type), but a pattern over the full (instruction, observation, thought, action) tuple. It is how a model reasons about and acts on the relational, functional, and visual properties of several on-screen regions at once, whether the screen is a static screenshot or a live application.
The behaviors from the opening, spatial reasoning, self-reflection, refutation, and instruction disambiguation, are specific gaps that follow from a distributional limitation. A model that never saw an example requiring spatial-relation reasoning will not acquire it, no matter how many screenshots it has seen. These behaviors live in the interaction between the instruction, the reasoning trace, and the visual input. They cannot be read off any one channel alone, which is why adding more of the same kind of data does not produce them.
Experimental Setup
Model: UI-TARS-1.5-7B with LoRA
We fine-tune UI-TARS-1.5-7B because it comes from the same model family we evaluated in Part 2 [13], allowing us to directly connect findings to training interventions.
We use a conservative LoRA configuration: rank 8, representing 0.042% of the model's trainable parameters which lets us test whether lightweight adaptation is sufficient for the representational shifts that GUI grounding requires.
Training Data
We build two training sets so we can hold scale fixed and vary only the kind of data: synthetic and targeted, against real and diverse.
- GUI-Perturbed (synthetic, targeted). We run the Part 1 perturbation pipeline, GUI-DR, over the Mind2Web [16] training set, then filter the output with Holo2-30B-A3B [15], the current ScreenSpot-Pro [17] state of the art at 66.1% accuracy. The split covers four perturbation types (style, text shrink, precision, and an all-combined mix) for 24,935 steps in total, summarized in table 1.
| Data Split | Variant Composition | Sample Size |
|---|---|---|
| 6.5k style | style | 6500 |
| 6.5k text shrink precision | text shrink + precision | 6500 |
| 6.5k all | style + text shrink + precision | 6500 |
| 25k all | style + text shrink + precision | 24935 |
- Salesforce GUI grounding mix (real, diverse). As a real-data baseline at matched scale, we sample 25k examples uniformly from the Salesforce GUI grounding dataset [14], which aggregates several open-source sources (table 2).
| Source Dataset | License |
|---|---|
| Aria-UI | Apache License 2.0 |
| OmniAct | MIT License |
| Widget Caption | Creative Commons Attribution 4.0 |
| UI-Vision | MIT License |
| OS-Atlas | Apache License 2.0 |
The two data sets allow us to fairly compare synthetic targeted data (GUI-Perturbed) against real diverse data (Salesforce mix) at matched scale. Both experiment 2 & 3 are evaluated on GUI-Perturbed and ScreenSpot-v2 [21].
Three experiments, three surprises
Experiment 1: Which Kinds of Perturbations Help?
Our first experiment compares augmentation variants to understand which types of perturbation data are most the most impactful on improving grounding. We train separate models on style-only perturbations, on text-shrink-and-precision perturbations, and on the full combined set.
The result is counterintuitive. All augmentations lead to slight degradation with text shrink precision only variant resulting in slightly more degradation on average as seen in figure 4. The most degradation (~3.3% with direct instruction and no reasoning) is seen on the text shrink variant in GUI-Perturbed eval set. One might expect text shrink perturbations to be the gentlest form of augmentation, changing text size and layout zoom level while preserving everything else. Instead, they produce the largest drop in grounding performance.
Experiment 2: Does More Data Help?
If targeted data helps even a little, more of it should help more, or at least do no harm.
The second experiment scales the training set from 6.5k to 25k samples to test whether more perturbation data improves performance. The standard expectation is that more data improves performance, or at worst plateaus it.
We observe amplified degradation due to scaling as seen in figures 5 and 6. More perturbed data widened the gap from baseline rather than closing it. This contradicts standard scaling intuitions and points to two interacting problems.
First, catastrophic forgetting: the distribution shift introduced by perturbed data compounds as the training set grows, pushing the model further from its original capabilities.
Second, the LoRA configuration memorizes noise from realistic perturbations instead of learning the invariances the perturbations were designed to teach. The low-rank constraint means the model has limited capacity for new representations, and it spends that capacity fitting artifacts rather than extracting generalizable patterns.
Experiment 3: Real Data vs Synthetic Data
If the problem with synthetic data is a distribution mismatch with real screens, real data should do better. The third experiment tests that directly, comparing the Salesforce mix (real, diverse, drawn from many open-source sets) against GUI-Perturbed (synthetic, targeted at specific perturbations) at the same scale.
As seen in figures 7 and 8, neither data set improve performance. Real diverse data degraded the model along different axes than synthetic perturbations, but both degraded it. That points away from the data and toward the recipe or something more fundamental about the model itself. Simple finetuning recipes cannot make the representational change GUI spatial reasoning needs: the model has to alter how it maps visual patches to spatial meaning, and that is a deeper change than a small percentage of its parameters can carry.
Discussion
GUI Models are More Sensitive to Data Distribution than Data Scale
The standard intuition in machine learning is that more diverse data leads to better generalization. What we observe with LoRA SFT on GUI grounding tasks is different: data scale and diversity matter less than distribution alignment with the target capability. Small amounts of misaligned data cause disproportionate degradation because the low-rank update has limited capacity and allocates it to fitting whatever signal is strongest in the training distribution, even if that signal is noise.
This has practical implications. Practitioners who collect or generate more data without carefully controlling its distributional properties may find that their models get worse, not better. Scale is not a substitute for alignment.
LoRA SFT is Insufficient for Visual-Spatial Alignment
GUI grounding requires shifting how the model relates visual patches to spatial semantics, a representational change at the model's feature level, not a behavioral adjusTRent that can be addressed with a LoRA. The findings are consistent with results from the DoRA paper on LoRA sensitivity, the analysis of fine-tuning representation shift for multimodal LLMs, and work on conditional mixture of LoRA approaches.
Cross-entropy loss alone may also be insufficient for grounding alignment. The loss optimizes next-token prediction over the action output, but it does not directly supervise the spatial reasoning that produces the correct action. A model can learn to produce plausible-looking coordinate outputs without improving its internal spatial representations.
Our baseline evaluation provides additional evidence. UI-TARS-1.5, trained on Qwen2.5VL-7B likely through further SFT and/or RL on CUA trajectory data (training details not public), achieves worse relational accuracy (35.0%) than the base Qwen2.5-VL (45.0%), despite improving on direct grounding. GTA1, which adds GRPO with step-level click reward on top of UI-TARS-1.5, recovers to 65.8%. The progression suggests that trajectory level supervised fine-tuning on GUI trajectories can improve direct element matching while degrading spatial reasoning, and that reinforcement learning with step-level grounding-specific reward is more effective at teaching geometric understanding.
Current Benchmarks Mask these Dynamics
Perhaps the most concerning finding is that without perturbation-based evaluation, we would not have detected these degradation patterns. Models that score well on fixed-scene benchmarks can degrade under training interventions that are designed to help them. If we had evaluated performance using only on standard benchmarks, we potentially would have arrived at a different conclusion.might have concluded that the training worked, or at least that it was harmless.
GUI-Perturbed as an evaluation tool is essential for honest measurement of training interventions. This reinforces our belief that perturbation-based data is not just useful for stress-testing models, it is necessary for understanding whether training is making progress on the capabilities that matter.
Scope and Limitations
Training method coverage. We evaluate LoRA at a single rank configuration. Full fine-tuning, higher-rank LoRA, QLoRA [18], and RL-based post-training (such as GRPO [14]) are all plausible alternatives that may yield different results. Our findings apply to the conservative LoRA regime that most practitioners use, but they should not be read as a general claim about all post-training methods.
Data coverage. We compare two data sources at matched scale. Broader augmentation strategies, curriculum-based approaches, and combinations of real and synthetic data remain unexplored.
What's Next
Behavior-Driven Data Curation
Today's CUA training data is organized by surface features: platform, application, element type. Our results argue for organizing it by the behaviors it teaches instead, visual reasoning, error correction, refutation, clarification, and spatial-relation reasoning.
Many of these behaviors are moving targets. They change with software updates, vary across tasks, and differ between users, and they show up through interaction rather than static annotation. Scaling behavioral coverage will likely take new curation methods: paraphrasing instructions for variety, auto-annotating interaction traces from user feedback, and building pipelines that ground training data in a desired distribution over instruction, observation, and behavior.
Better Post-Training Recipes
LoRA SFT with cross-entropy loss is not enough on its own. The directions we find most promising combine stages and signals: multi-stage training that pairs SFT with RL (as in SpatialLadder [19] and GuirlVG [20]), higher-rank adaptation that gives the model more room for representational change, and process reward models that supervise grounding decisions step by step rather than scoring a whole sequence at once.
Richer Learning Signals from Environment State
Current GUI training operates on a simple mapping: (screenshot, instruction) produces an action. What is missing is a representation of the next state, the result of taking that action. Without next-state information, the model has no way to learn from the consequences of its actions during training.
Better computer state representations could unlock richer credit assignment and more efficient learning signals. This connects back to the domain randomization thesis from Part 1: just as robotic policies benefit from simulators that provide full state feedback, GUI agents could benefit from environment representations that go beyond static screenshots. Building those representations is a direction we are actively exploring at Fig.
Conclusion
Across this series, developed a new domain randomization approach for GUI data, used it to expose systematic weaknesses in state-of-the-art models, and, in this work, attempted to fix those weaknesses through training.
While the training results negatively impacted model performance, they were very informative. We learned that naive data augmentation with conservative fine-tuning does not close the behavioral gaps we identified. Style perturbations degrade rather than improve, more data amplifies the effect, and real data vs. synthetic data both fail when the training recipe cannot support the representational changes the task requires.
The path forward requires rethinking both training data coverage and how models learn from it. On the data side, we need to evolve from surface-level diversity (more platforms, more applications) to behavioral diversity (more reasoning patterns, more failure recovery, more spatial understanding). On the training side, we need recipes that go beyond LoRA SFT: higher-capacity adaptation, reinforcement learning from grounding feedback, and learning signals that capture the consequences of actions rather than just the actions themselves.
Work With Us
At Fig, we are building the control layer for AI: systems that perceive an environment, act in it reliably, and improve from the experience. Perception is largely solved. Agency is the open problem: acting dependably in real environments, recovering from mistakes, and compounding over time. It will not come from scaling language models, and as this post shows, it will not come from bolting a prompt or a light fine-tune onto a model that never learned the behavior in the first place.
Subscribe to stay updated as we make progress! If you'd like to work on the next frontier of intelligent systems, reach out!
Citation
Please cite this work as follows:
@online{training_on_gui_perturbed_technical_report_2026,
title = {Fixing Failures in Browser-Use Models: Why More Data Isn't Enough},
author = {Yangyue Wang and Harshvardhan Sikka and Yash Mathur and Tony Zhou and Jinu Nyachhyon and Pranav Guruprasad},
year = {2026},
url = {www.fig.inc/blog/fixing-failures-in-browser-use/},
note = {Part 3: Finetuning Experiments}
}References
[1] "Overview," Agent Skills. Accessed: Mar. 10, 2026.
[2] Y. Qin et al., "UI-TARS: Pioneering Automated GUI Interaction with Native Agents," arXiv.org. Accessed: Mar. 10, 2026.
[3] J. Mu et al., "GUI-360°: A Comprehensive Dataset and Benchmark for Computer-Using Agents," Nov. 10, 2025, arXiv. doi: 10.48550/arXiv.2511.04307.
[4] H. Li, J. Chen, J. Su, Y. Chen, Q. Li, and Z. Zhang, "AutoGUI: Scaling GUI Grounding with Automatic Functionality Annotations from LLMs," Jun. 07, 2025, arXiv. doi: 10.48550/arXiv.2502.01977.
[5] S. Nayak et al., "UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction," May 06, 2025, arXiv. doi: 10.48550/arXiv.2503.15661.
[6] X. Wang et al., "OpenCUA: Open Foundations for Computer-Use Agents," Oct. 04, 2025, arXiv. doi: 10.48550/arXiv.2508.09123.
[7] T. Xie et al., "Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis," Oct. 24, 2025, arXiv. doi: 10.48550/arXiv.2505.13227.
[8] E. J. Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models," Oct. 16, 2021, arXiv. doi: 10.48550/arXiv.2106.09685.
[9] G. Pantazopoulos and E. B. Özyiğit, "An Efficient Training Pipeline for Reasoning Graphical User Interface Agents," Nov. 14, 2025, arXiv. doi: 10.48550/arXiv.2511.08172.
[10] S.-Y. Liu et al., "DoRA: Weight-Decomposed Low-Rank Adaptation," Jul. 09, 2024, arXiv. doi: 10.48550/arXiv.2402.09353.
[11] Y. Peng, P. Wang, J. Liu, and S. Chen, "GLAD: Generalizable Tuning for Vision-Language Models," Jul. 17, 2025, arXiv. doi: 10.48550/arXiv.2507.13089.
[12] T. Xue et al., "EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience," Jan. 23, 2026, arXiv. doi: 10.48550/arXiv.2601.15876.
[13] "ByteDance-Seed/UI-TARS-1.5-7B," Hugging Face. Accessed: Mar. 10, 2026.
[14] Y. Yang et al., "GTA1: GUI Test-time Scaling Agent," Oct. 03, 2025, arXiv. doi: 10.48550/arXiv.2507.05791.
[15] "Hcompany/Holo2-30B-A3B," Hugging Face. Accessed: Mar. 10, 2026.
[16] X. Deng et al., "Mind2Web: Towards a Generalist Agent for the Web," Dec. 09, 2023, arXiv. doi: 10.48550/arXiv.2306.06070.
[17] K. Li et al., "ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use," Apr. 04, 2025, arXiv. doi: 10.48550/arXiv.2504.07981.
[18] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, "QLoRA: Efficient Finetuning of Quantized LLMs," May 23, 2023, arXiv. doi: 10.48550/arXiv.2305.14314.
[19] H. Li et al., "SpatialLadder: Progressive Training for Spatial Reasoning in Vision-Language Models," Oct. 09, 2025, arXiv. doi: 10.48550/arXiv.2510.08531.
[20] W. Kang, B. Lei, G. Liu, C. Ding, and Y. Yan, "GuirlVG: Incentivize GUI Visual Grounding via Empirical Exploration on Reinforcement Learning," Aug. 06, 2025, arXiv. doi: 10.48550/arXiv.2508.04389.
[21] K. Cheng et al., “SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents,” Feb. 23, 2024, arXiv: arXiv:2401.10935. doi: 10.48550/arXiv.2401.10935.
