GUI-Perturbed: Breaking Browser-use Models using Domain Randomization
Yangyue Wang1, 2, Harshvardhan Sikka1, 2, Yash Mathur*2, Tony Zhou*2, Jinu Nyachhyon*2, Pranav Guruprasad1, 2
* Equal contributions. 1Fig; 2Manifold Research Group.
TL;DR
- We introduce a baseline study of 7B GUI models using GUI-Perturbed to stress test CUA models and understand what agents fail at and why.
- A detailed failure mode analysis showcases common GUI failure modes from spatial reasoning, false visual heuristics to CoT reasoning's effect.
GUI Perturbation — Research Series
GUI models scoring above 90% on ScreenSpot-v2 fail to find the target element when you set web page zoom to 70% [1]. Same website, same layout, same UI elements. Just smaller.
These models were trained on hundreds of thousands to millions of GUI screenshots through supervised fine-tuning and reinforcement learning stages yet they still cannot adapt to a change in zoom.
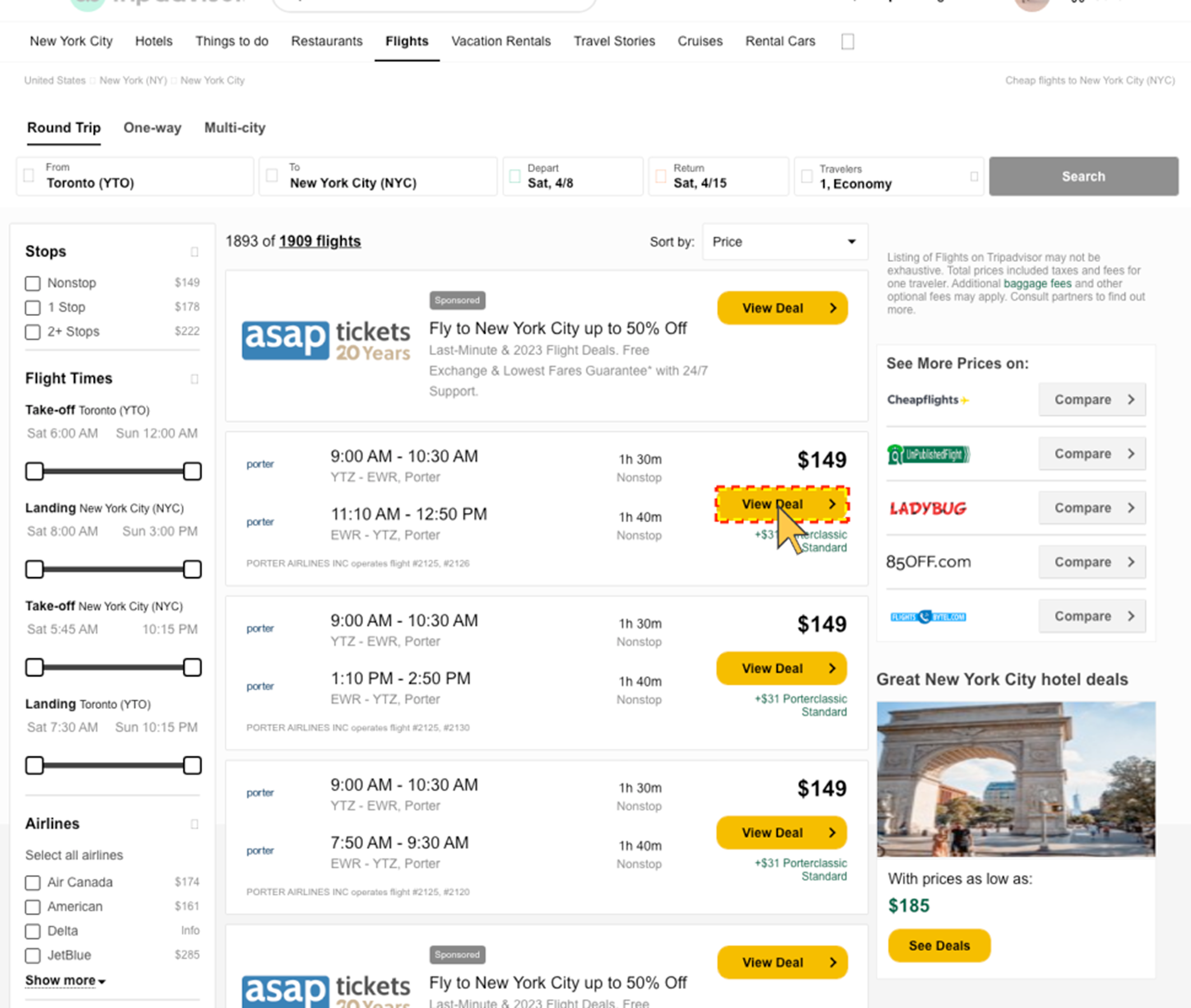
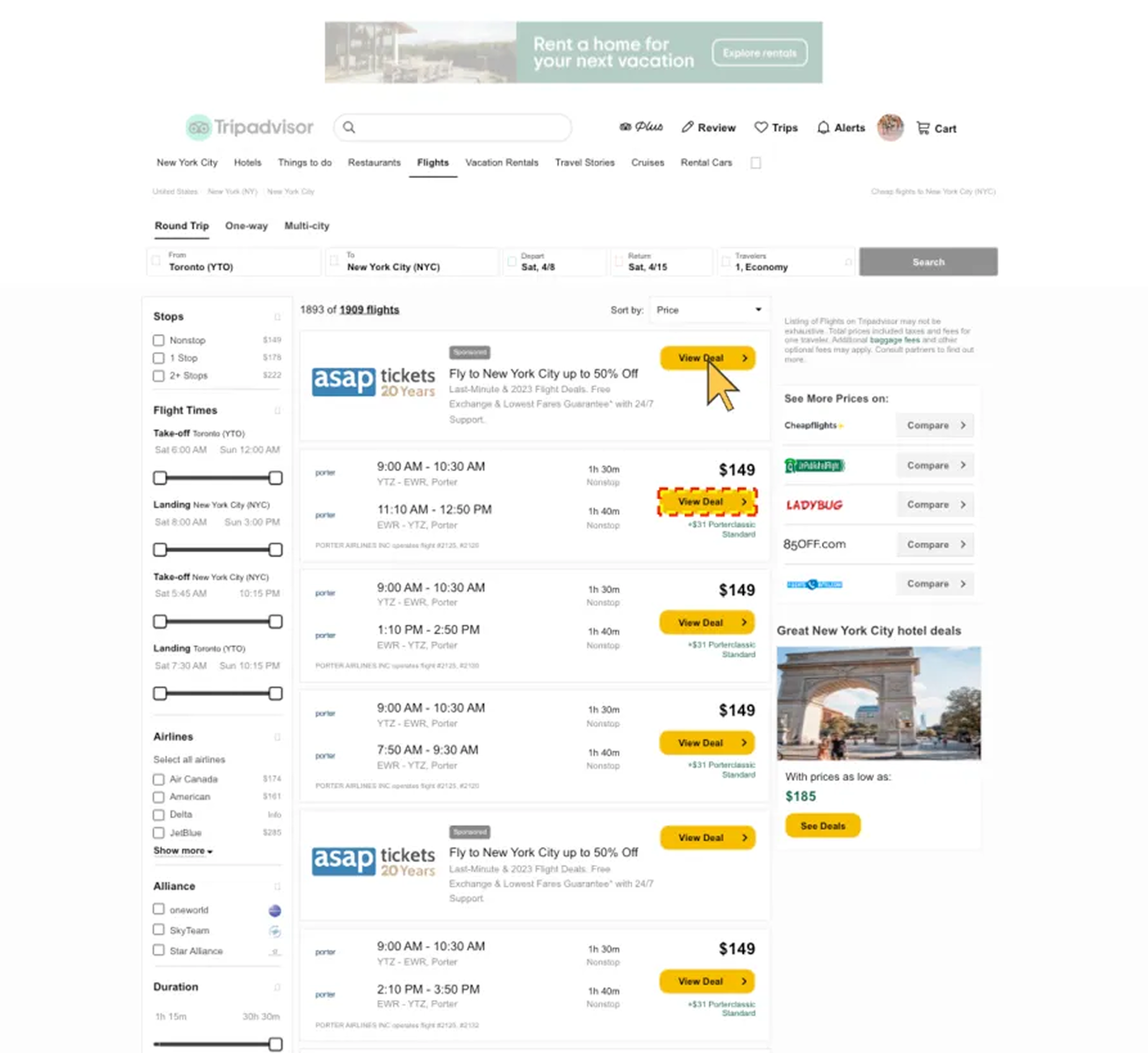
Figure 1: Sample: 21 of 390: "Click on 'View Deal' button for flight '#2125, #2126'", Direct Instruction, No Reasoning. Result: UI-TARS1.5-7B clicked on the fake 'view deal' button in the ads after the 70% zoom.
GUI grounding looks solved. On fixed-scene benchmarks like ScreenSpot-v2, 7B models now score above 90%, and it is tempting to read those numbers as evidence that perception is no longer the bottleneck for computer-use agents (CUAs). The numbers are real, but they are measured on screens that never move. Real users zoom, restyle, and resize, and production websites are redesigned constantly. The question the industry should care about is not how well a model does on a frozen screenshot, but how much of that performance survives contact with ordinary variation.
So we ask one question: how much of a GUI grounding model's benchmark accuracy is stable under perturbation, and how much of it is memorized? Because the three models we study share a base checkpoint but differ in post-training, we can ask a sharper version too: does each additional stage of GUI-specialized post-training buy real robustness, or does it only raise the fixed-scene score?
Our goal here is to separate those two things. In Part 1, we introduced GUI-DR, a data augmentation pipeline that varies visual scenes and instructions along controlled axes to stress test CUA model's GUI grounding capability. In this post, we use it to create a dataset composed of visual scene and the instruction variations created along controlled axes. This dataset serves as a benchmark to evaluate three state-of-the-art models that share the same base checkpoint but differ in their post-training recipes, and we report where they break. We find that:
- Visual perturbations degrade models that benchmarks call production-ready. A change as small as setting browser zoom to 70% drops accuracy by 2 to 6 points across all three models.
- Spatial relational instructions are the weakest point. Asking for "the button above X" instead of "the submit button" costs 27 to 56 points, the largest single effect we see.
- Reasoning is not uniformly good. A chain of thought helps on hard relational tasks and hurts on easy direct ones, and a model post-trained for direct coordinate prediction is harmed by it everywhere.
- More GUI-specialized post-training does not fix any of this. The same weaknesses persist from the base model through two further stages of GUI training.
The Triple Alignment Problem
Grounding a GUI instruction is harder than it looks, because the model has to align three different things at once and a benchmark score collapses all three into one number.
- Visual alignment: identifying an element's appearance in pixel space, its shape, color, size, and boundaries.
- Functional alignment: knowing what the element does, telling an input field from a display label or a clickable button from a static icon.
- Geometric alignment: resolving spatial relationships between elements, "above," "next to," "the one between X and Y."
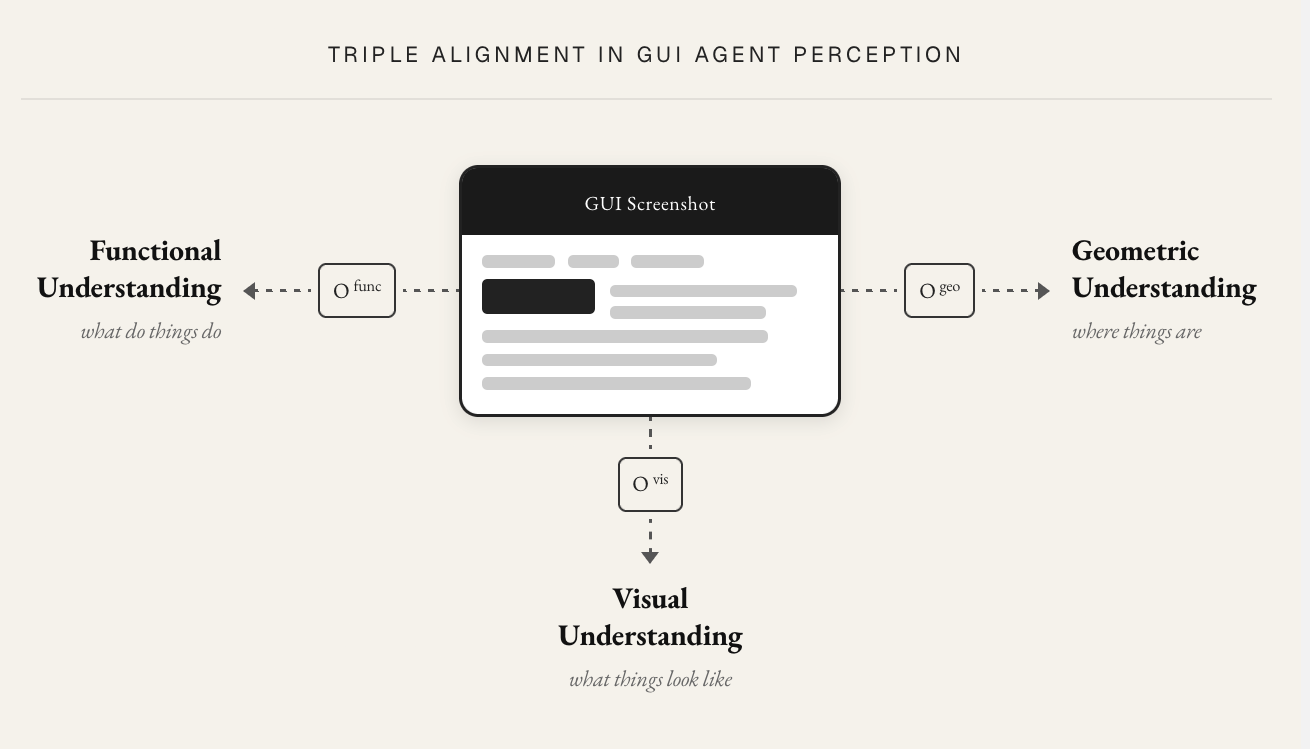
Most benchmarks test the three entangled together [2, 3], so when a model fails the score cannot say which alignment broke. GUI-Perturbed is built to stress visual and geometric alignment independently, which lets us attribute a failure to one axis rather than guess. (Our current perturbations do not isolate functional alignment the way AutoGUI's instructions do [4]; we leave that for future work.)
This framing carries through the rest of the post. For every result, we name the alignment axis it implicates.
Problem Formulation
A computer-use agent acts over many steps: it sees a screen, picks an action, the screen changes, and it sees the next one. That full setting is a partially observable Markov decision process (POMDP) [9-11], and recent agentic models are trained against it [12, 13]. We do not need the full machinery here, because our evaluation isolates a single step.
The POMDP tuple defines the CUA problem structure: hidden app states, observations (screenshots + goal), actions, transition dynamics, and reward [12].
\[ \mathcal{M} \;=\; \langle\, \mathcal{S},\; \mathcal{A},\; \mathcal{O},\; \underbrace{\mathcal{T}(s_{t+1}\mid s_t, a_t)}_{\text{transition}},\; \mathcal{R} \,\rangle \]At each step, a CUA model receives an instruction I and an observation OO (the screenshot), optionally produces a chain of thought T, and outputs an action A. The full step can be written as:
\[ O_t \;\sim\; \mathcal{Z}(O_t \mid s_t), \qquad (t_t,\, a_t) \;=\; \mathrm{VLM}_\theta\!\left( I,\; O_{1:t},\; t_{1:t-1},\; a_{1:t-1} \right), \quad I \in \mathcal{I} \]Triple alignment is the key representational challenge: to select a correct action at at , the model must be able to interpret Ot along three axes visual appearance, geometric relation, functional affordance of the GUI from screenshots simultaneously.
\[ a_t \;=\; \pi_\theta\!\left(I,\; O_{1:t},\; t_{1:t-1},\; a_{1:t-1} \right), \qquad O_t \;\supseteq\; \left(\, \underbrace{O_t^{\mathrm{vis}}}_{\substack{\text{visual}\\\text{appearance}}},\; \underbrace{O_t^{\mathrm{geo}}}_{\substack{\text{geometric}\\\text{layout}}},\; \underbrace{O_t^{\mathrm{func}}}_{\substack{\text{functional}\\\text{affordance}}} \,\right) \]Our evaluation isolates the grounding step: given (I,O), predict the correct element. This removes multi-step dependencies and focuses the evaluation on the single-step alignment problem described above. We do evaluate models in both reasoning and no-reasoning configurations, which introduces a planning-like component through the thought trace T, and we report on its effects below.
Experimental Setup
Three Models, One Base Checkpoint
We study three 7B models built on the same base weights, so that any difference in robustness is attributable to post-training rather than to scale or architecture:
- Qwen2.5-VL-7B, the base vision-language model (VLM). It saw some GUI trajectories during long-context pre-training but had no dedicated GUI fine-tuning [5].
- UI-TARS-1.5-7B, initialized from Qwen2.5-VL and trained further on end-to-end GUI trajectories [8]. The exact recipe is not public; the UI-TARS papers [6] point to supervised fine-tuning (SFT) and reinforcement learning.
- GTA1-7B, initialized from UI-TARS-1.5 and trained further on GUI data with step-level Group Relative Policy Optimization (GRPO) [7].
| Qwen2.5VL-7B | UI-TARS1.5-7B | GTA1-7B | |
|---|---|---|---|
| Architecture | |||
| Base model | Qwen2.5VL-7B | Qwen2.5VL-7B | UI-TARS1.5-7B (grounding) + o3 (planner) |
| Training | |||
| Stages |
|
Based on UI-TARS recipe, UI-TARS1.5 training recipe not public [7]
|
RL Optimization:
|
| Training Data | |||
| Volume | 4.1T tokens | $\sim$50B tokens | — |
| Sources |
|
|
|
We chose this lineage deliberately, the models share the same architecture and same base weights with different training recipes. Any performance variation between the three is directly attributable to post-training, not architecture, which allows us to precisely ask: how does each additional stage of GUI-specialized training affect robustness under perturbation?
Stress Test Matrix
We evaluate three 7-B models from the same lineage on eight task variants from GUI-Perturbed, enabling comparisons along three axes visual variants, instruction types, and reasoning mode:
| Axis | Levels | Cardinality |
|---|---|---|
| Visual Perturbation | \(\{\text{Original},\ \text{Style},\ \text{Precision},\ \text{Text Shrink}\}\) | 4 |
| Instruction Type | \(\{\text{Directional},\ \text{Relational}\}\) | 2 |
| Reasoning Mode | \(\{\text{With CoT},\ \text{Without CoT}\}\) | 2 |
| Total Configurations per Model | $4 \times 2 \times 2 = 16$ | |
Evaluation Metrics
We focus our analysis primarily on hit rate, flip rate, and net delta, which measure the models' overall performance and sensitivity under perturbation:
- Hit rate measures whether the predicted coordinate falls within the bounding box of the target element. We report 95% bootstrap confidence intervals (10,000 resamples) for all hit rates; exact binomial (Clopper--Pearson) intervals agreed within 0.2 pp throughout and are omitted for brevity. This is our primary metric: a grounding prediction either lands on the right element or it does not.
- Flip rate measures the fraction of matched pairs whose binary outcome (hit/miss) changed between the original and the perturbed condition. Each perturbation test uses n = 390 matched sample pairs (same task and step evaluated on both the original and perturbed screenshots). A high flip rate indicates the model's output is sensitive to the perturbation, regardless of whether accuracy improves or degrades on average.
- Net Delta measures the difference in hit rate between the original and perturbed conditions (original minus perturbed), with 95% bootstrap CI. A positive Delta indicates overall degradation.
We also test significance with McNemar's test, which compares the number of samples that degraded (b: correct to incorrect) against those that improved (c: incorrect to correct) under perturbation, ignoring samples whose outcome did not change. We report p-values with continuity correction; when the number of discordant pairs (b + c) is below 25, we use the exact binomial test instead.
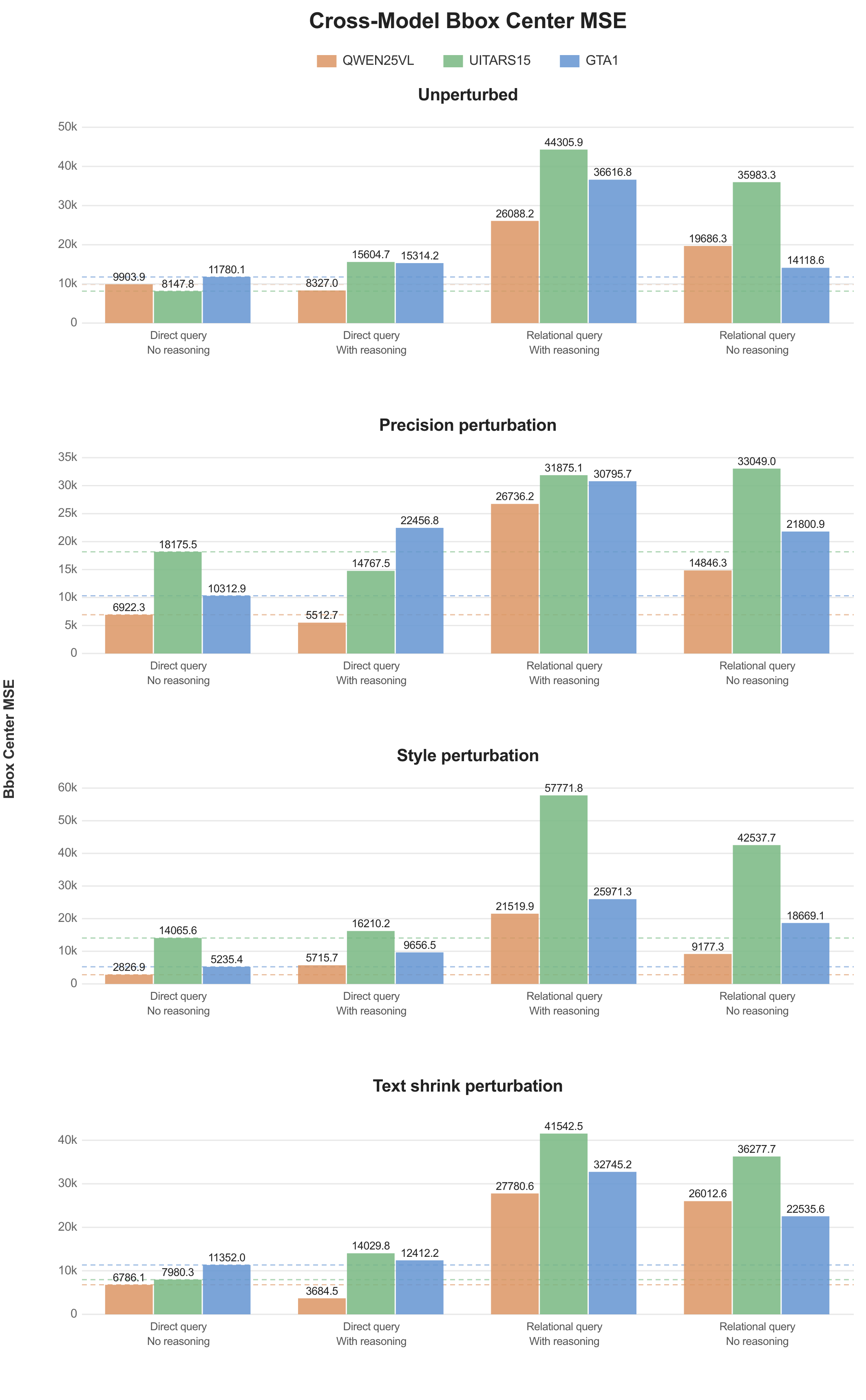
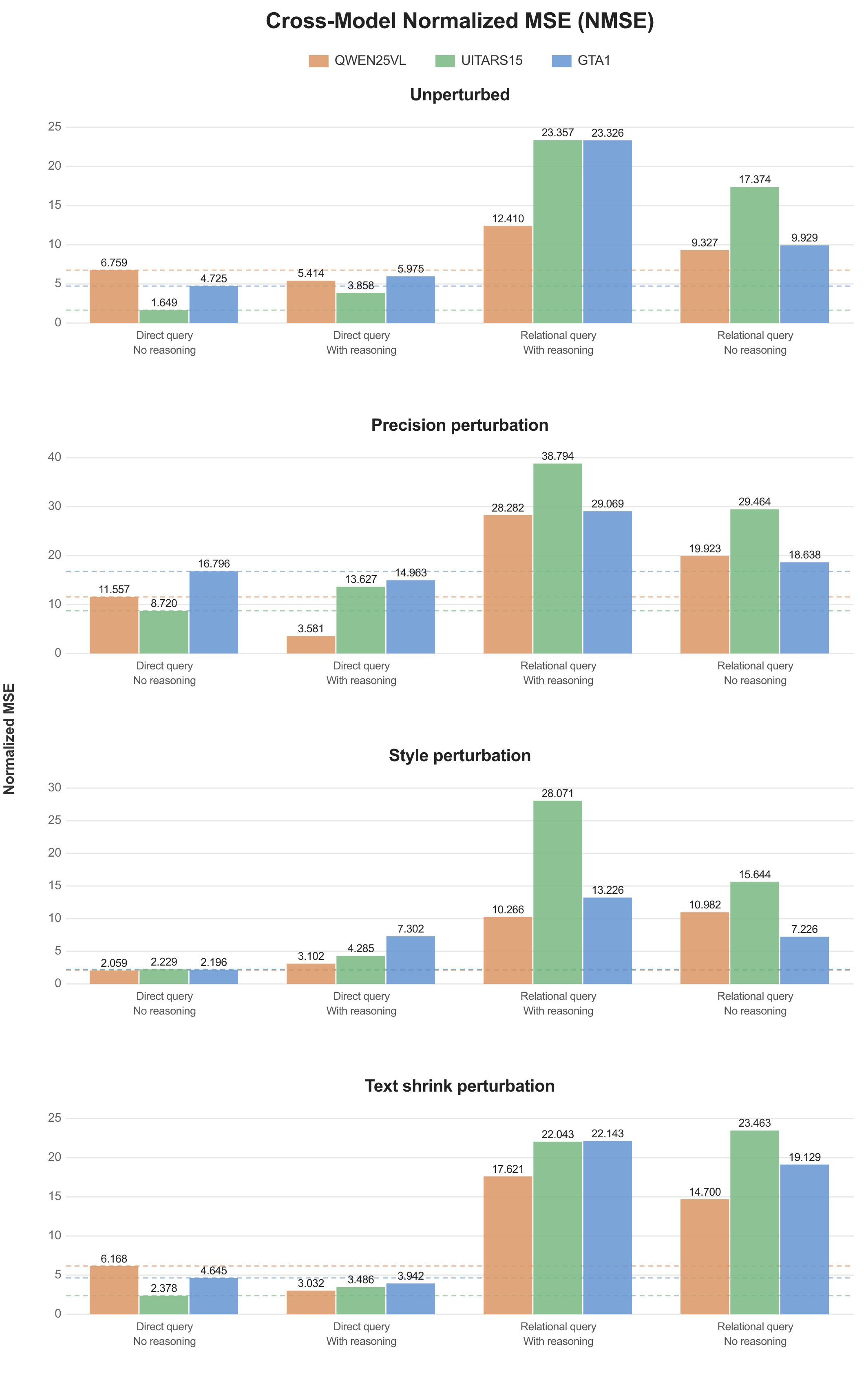
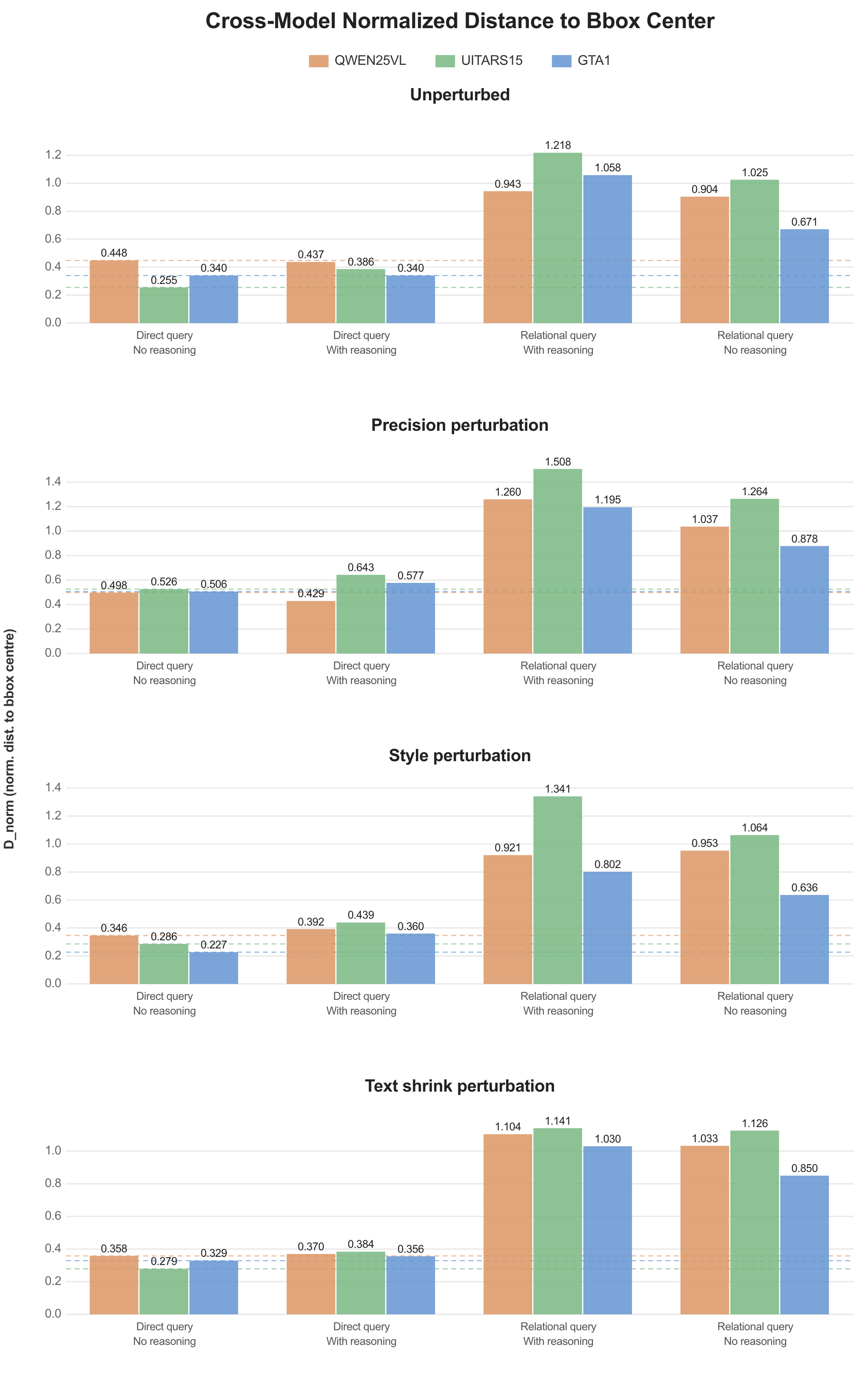
Additionally, MSE, normalized MSE, and normalized distance provide additional signal on error magnitude but did not reveal trends beyond what the primary metrics capture.
Results
Visual Perturbations Break Models that Benchmarks Call Robust
All three models degrade under visual perturbations, including a change as small as browser zoom. Models scoring above 90% on fixed-scene benchmarks drop on perturbed versions of the same pages.
| Flip Rate | Net $\Delta$ (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Pert. | Base Acc. | Dir. | Rel. | Dir. | Rel. | $\boldsymbol{b}$ / $\boldsymbol{c}$ | Sig. |
| GTA-1 | Precision | 79.3 | 10.3% | 21.5% | +3.6** | +7.9*** | 169/79 | 3/4 |
| Style | 9.7% | 21.5% | +1.3 | −0.3 | 126/118 | 0/4 | ||
| Text Shrink | 4.2% | 16.7% | +0.4 | +1.8 | 90/73 | 0/4 | ||
| Qwen2.5-VL | Precision | 66.0 | 13.1% | 16.4% | +3.3 | +4.9* | 147/83 | 2/4 |
| Style | 8.7% | 19.1% | +2.8** | +0.1 | 120/97 | 1/4 | ||
| Text Shrink | 7.8% | 14.4% | +0.1 | +2.8 | 98/75 | 0/4 | ||
| UI-TARS-1.5 | Precision | 63.0 | 13.1% | 18.7% | +6.2*** | +5.4** | 169/79 | 4/4 |
| Style | 11.2% | 19.2% | +2.4 | +1.0 | 132/105 | 0/4 | ||
| Text Shrink | 6.9% | 14.1% | −0.8 | +0.0 | 79/85 | 0/4 | ||
The zoom and text-size perturbations are worth emphasizing as they are not exotic transformations. Any user adjusting their browser zoom or system font size produces exactly this kind of variation. The fact that models trained on millions of GUI screenshots cannot handle a zoom change suggests they are memorizing absolute spatial positions rather than understanding relational structure.
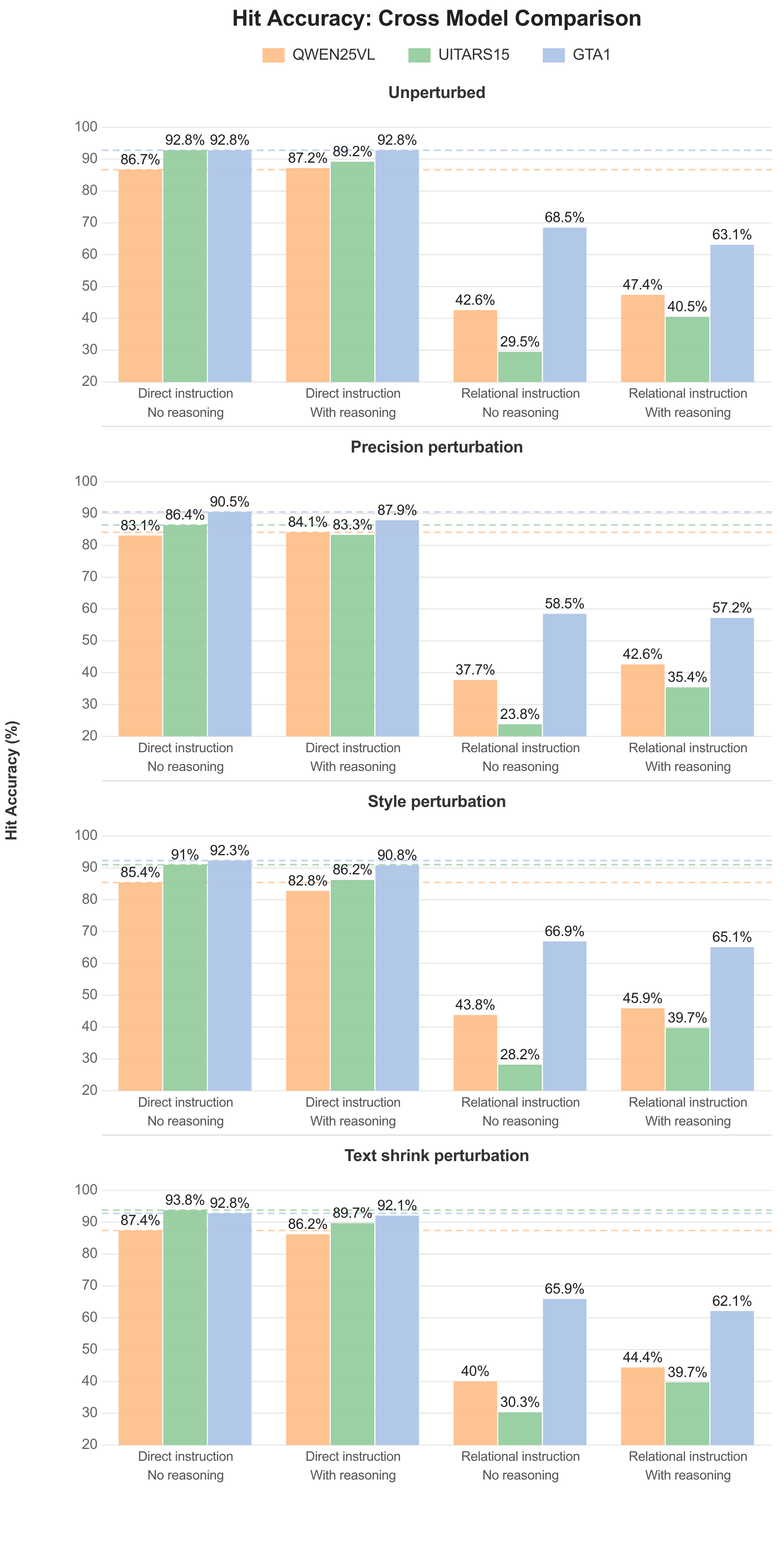
Spatial Reasoning is the Weakest Link
The sharpest performance drops come from relational instruction variants. When the instruction asks the model to identify an element by its spatial relationship to a neighbor (“click the button above X”), performance falls well below what the same models achieve on direct instructions (“click the submit button”).
| Benchmark | Qwen2.5VL-7B | UI-TARS1.5-7B | GTA1-7B |
|---|---|---|---|
| ScreenSpot-v2 | 88.8 | 89.7 | 92.4 |
| ScreenSpot-Pro | 27.6 | 42.0 | 50.1 |
| OSWorld | — | $27.4 \pm 2.2\%$ | 45.2 (with o3) |
| OSWorld-G | 27.7 | 64.2 | 67.7 |
| GP-Unperturbed (Direct) | 86.9 | 91.0 | 92.8 |
| GP-Unperturbed (Relational) | 45.0 (↓\(-41.9\)) | 35.0 (↓\(-56.0\)) | 65.8 (↓\(-27.1\)) |
We also examined whether models exhibit systematic directional biases in their spatial errors. Our directional hit rate analysis shows that models perform unevenly across spatial directions, with consistently higher accuracy on instructions involving the direction “right” compared to other directions.
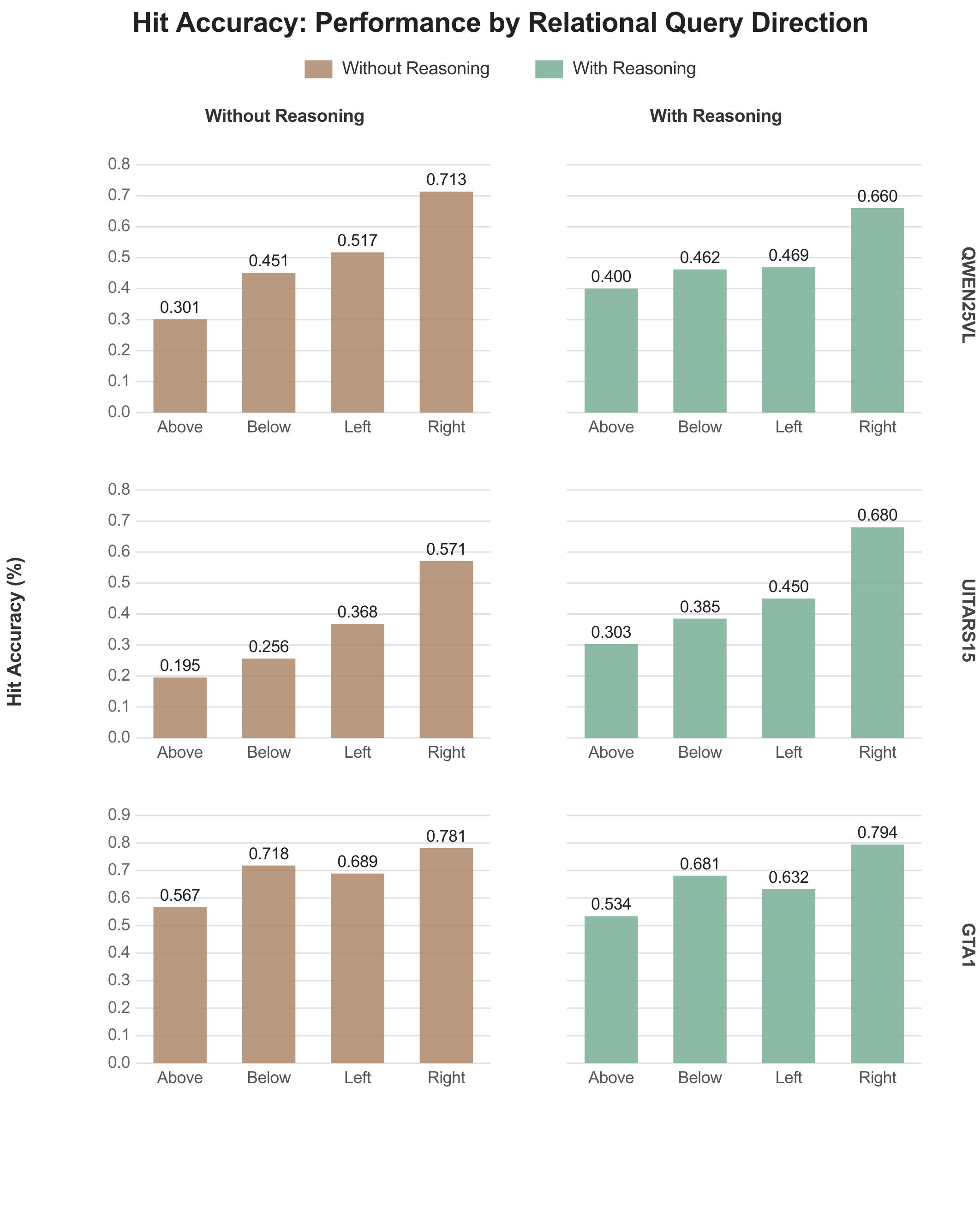
We note that our directional analysis relies partly on manual labeling to correct reference landmark coordinates, which limits the scale at which we can draw conclusions. The directional asymmetry we observe is suggestive of biases introduced during training or by the visual patchification process, but confirming this would require a larger controlled study.
Reasoning Helps on Hard Tasks, Hurts on Easy Ones
The effect of reasoning mode is not uniformly positive. Enabling reasoning (the thought trace TT in our formulation) produces different outcomes depending on task difficulty.
On simple direct grounding tasks, reasoning introduces unnecessary deliberation that can actively mislead the final prediction. The model “overthinks” a task that the base visual grounding would handle correctly without intermediate reasoning.
On more complex relational tasks, reasoning recovers some performance by providing useful intermediate structure: the model can reason about spatial relationships step by step rather than attempting to resolve them in a single forward pass.
GTA1 provides a particularly instructive case. It was further trained to predict coordinates directly, and it suffers degradation from reasoning on both simple and harder relational tasks. Its post-training has optimized it for direct coordinate prediction, and the reasoning trace interferes with that pipeline regardless of task complexity.
The implication is that blanket “enable reasoning” is not the right strategy. Models need exposure to diverse reasoning styles during post-training, and they need to calibrate when to reason and how much. The optimal reasoning style and length likely varies by task.
Failure Mode Taxonomy
We conducted a qualitative analysis of representative failures across all models and configurations. Several recurring patterns emerge.
| Failure Mode | Definition |
|---|---|
| spatialClick Region Error | The model selects the correct UI element conceptually but clicks the wrong physical area of it. |
| spatialLocation Hallucination | The model correctly identifies what to click but fabricates or misplaces its on-screen coordinates. |
| reasoningReasoning Drift | Adding explicit reasoning causes the model's grounded action prediction to deteriorate. |
| semanticGoal Hallucination | The model invents user intentions or interface functionality not specified in the instruction. |
| semanticInstruction Misinterpretation | The model misunderstands what the instruction refers to and selects a related but incorrect element. |
| visualVisual Confusion | The model relies on superficial visual cues (shape, color, position) and misidentifies the functional element. |
| spatialSpatial Reasoning Error | The model incorrectly interprets relative spatial relationships such as left, right, above, or below. |
| semanticText Matching Bias | The model interacts with visible text matching the instruction without properly grounding it to the correct UI element. |
Discussion
Models Lack Spatial Relational Understanding
The sharpest performance drops in our evaluation come from relational instructions. Models can find an element by name but cannot resolve “the field above X.” This is not a data quantity problem. These models have been trained on millions of screenshots. The issue is representational: current architectures do not build structured spatial models of GUI layouts. They encode visual features at the patch level without maintaining an explicit spatial graph of element relationships.
This maps directly to the geometric alignment axis from our framing. Visual and functional alignment may be adequate for direct grounding tasks, but geometric alignment, the ability to reason about spatial relationships between elements, is where current models fall short.
Visual Heuristics are Static and Fragile
Models learn fixed visual associations (white rectangle at the top of the screen equals search bar) that break on any layout or style change. In the zoom perturbation results, we see models clicking on advertisement elements that happen to occupy the spatial position where the target element used to be at the original zoom level. The model has memorized a position, not learned a function.
In production, websites update their designs regularly. A model relying on static visual heuristics is one deployment away from failure. This is a visual alignment problem: the model’s visual representations are too tightly coupled to the specific pixel-level appearances in the training distribution.
Reasoning is a Double-Edged Sword for Grounding
Pulling the reasoning results together: deliberation helps on hard relational tasks and hurts on easy direct ones, and GTA-1 sharpens the point. A model post-trained for direct coordinate prediction is harmed by reasoning in every condition, because the trace disrupts the pipeline its training optimized for.
The implication for post-training is that reasoning should be treated as a learnable, task-conditioned skill rather than a switch to flip on or off. Models need exposure to varied reasoning styles and lengths during training so they can learn when deliberation helps and when it does not.
Scope and Limitations
Model coverage. We evaluate three models from one base checkpoint lineage and while this approach isolates the effect of post-training recipes, it may not generalize to models with different base architectures or scales. Broader coverage is future work.
Perturbation coverage. We evaluate on eight variants from GUI-Perturbed. More perturbation types and combinations are possible, and interactions between perturbation types (ex: zoom combined with relational instructions) remain unexplored.
What’s Next
This report used GUI-Perturbed as a benchmark to uncover systematic weaknesses in state-of-the-art GUI grounding models that persist across all three models despite increasingly specialized post-training.
Part 3 will explore the natural next question: whether we can fix these weaknesses with better training data. We use GUI-Perturbed for data augmentation and measure whether targeted training closes the gaps we identified here.
At Fig, we're building the control layer for AI: systems that perceive an environment, act in it reliably, and improve from the experience. Frontier models have largely solved perception. Agency is the open problem — acting dependably in real environments, recovering from mistakes, and compounding over time — and it will not come from scaling language models alone. Computer use is where we begin, and grounding is where the gap first surfaces: a model that can read a screen but cannot reliably act on it is not yet in control. GUI-Perturbed measures that gap precisely. Closing it, across software today and every environment over time, is the work ahead.
Subscribe to stay updated as we make progress! If you'd like to get involved, reach out to contact@fig.inc
Citation
Please cite this work as:
@online{measuring_gui_models_robustness_technical_report_2026,
title = {GUI-Perturbed: Breaking Browser-use Models using Domain Randomization},
author = {Yangyue Wang and Harshvardhan Sikka and Yash Mathur and Tony Zhou and Jinu Nyachhyon and Pranav Guruprasad},
year = {2026},
url = {www.fig.inc/blog/gui-pertubed-breaking-browser-use-models/},
note = {Part 2: Baseline evaluation}
}References
[1] K. Cheng et al., "SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents," Feb. 23, 2024, arXiv: arXiv:2401.10935. doi: 10.48550/arXiv.2401.10935.
[2] T. Xie et al., "OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments," May 30, 2024, arXiv: arXiv:2404.07972. doi: 10.48550/arXiv.2404.07972.
[3] K. Li et al., "ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use," Apr. 04, 2025, arXiv: arXiv:2504.07981. doi: 10.48550/arXiv.2504.07981.
[4] H. Li, J. Chen, J. Su, Y. Chen, Q. Li, and Z. Zhang, "AutoGUI: Scaling GUI Grounding with Automatic Functionality Annotations from LLMs," Jun. 07, 2025, arXiv: arXiv:2502.01977. doi: 10.48550/arXiv.2502.01977.
[5] S. Bai et al., "Qwen2.5-VL Technical Report," Feb. 19, 2025, arXiv: arXiv:2502.13923. doi: 10.48550/arXiv.2502.13923.
[6] Y. Qin et al., "UI-TARS: Pioneering Automated GUI Interaction with Native Agents," Jan. 21, 2025, arXiv: arXiv:2501.12326. doi: 10.48550/arXiv.2501.12326.
[7] Y. Yang et al., "GTA1: GUI Test-time Scaling Agent," Oct. 03, 2025, arXiv: arXiv:2507.05791. doi: 10.48550/arXiv.2507.05791.
[8] U.-T. Team, "UI-TARS - Next-generation native GUI agent model," UI-TARS. Accessed: Mar. 04, 2026.
[9] M. Lu et al., "Scaling Agentic Reinforcement Learning for Tool-Integrated Reasoning in VLMs," Nov. 24, 2025, arXiv: arXiv:2511.19773. doi: 10.48550/arXiv.2511.19773.
[10] L. Zhao et al., "Seeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators," Apr. 04, 2025, arXiv: arXiv:2504.03245. doi: 10.48550/arXiv.2504.03245.
[11] H. Li et al., "VLA-RFT: Vision-Language-Action Reinforcement Fine-tuning with Verified Rewards in World Simulators," Oct. 01, 2025, arXiv: arXiv:2510.00406. doi: 10.48550/arXiv.2510.00406.
[12] J. Wu et al., "OS-Marathon: Benchmarking Computer-Use Agents on Long-Horizon Repetitive Tasks," Feb. 02, 2026, arXiv: arXiv:2601.20650. doi: 10.48550/arXiv.2601.20650.
[13] K. Team et al., "Kimi K2.5: Visual Agentic Intelligence," Feb. 02, 2026, arXiv: arXiv:2602.02276. doi: 10.48550/arXiv.2602.02276.
[14] B. Oliveira and C. Teixeira Lopes, "The Evolution of Web Search User Interfaces - An Archaeological Analysis of Google Search Engine Result Pages," in Proceedings of the 2023 Conference on Human Information Interaction and Retrieval, Austin TX USA: ACM, Mar. 2023, pp. 55–68. doi: 10.1145/3576840.3578320.
[15] Y. Yang et al., "Aria-UI: Visual Grounding for GUI Instructions," 2024, arXiv: arXiv:2412.16256.
[16] R. Kapoor et al., "OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web," 2024, arXiv: arXiv:2402.17553.
[17] Y. Li et al., "Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements," in Proc. EMNLP, 2020, pp. 5495–5510.
[18] S. Nayak et al., "UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction," 2025, arXiv: arXiv:2503.15661.
[19] Z. Wu et al., "OS-ATLAS: A Foundation Action Model for Generalist GUI Agents," 2024, arXiv: arXiv:2410.23218. doi: 10.48550/arXiv.2410.23218.
Appendix
1. Model Performance with MSE, NMSE, and D_norm (Normalized Distance)