Domain Randomization for Computer Control
Yangyue Wang1, 2, Harshvardhan Sikka1, 2, Yash Mathur*2, Tony Zhou*2, Jinu Nyachhyon*2, Pranav Guruprasad1, 2
* Equal contributions. 1Fig; 2Manifold Research Group.
GUI-DR restyles, repositions, and removes DOM elements on real webpages
TL;DR
- GUI models scoring 90%+ on standard benchmarks fail under basic visual variations like a 70% browser zoom. Current benchmarks can't detect this because they evaluate on fixed scenes with fixed instructions. We quantify how far performance drops in Part 2. Subscribe to get it in your inbox.
- Our stress-testing framework for GUI grounding applies domain randomization from robotics, varying visual scenes and instructions along controlled axes to expose fragile model behaviors.
- We introduce GUI-DR, an open-source data augmentation pipeline for generating perturbation variants from real web pages.
The White Rectangle Problem
Modern GUI grounding models can locate a “Submit” button with high precision, identify form fields from natural-language instructions, and navigate complex web interfaces. Yet they confuse a browser's search bar with the formula bar in Google Sheets. Both are white rectangles near the top of the screen. Mistakes like these are the demo-to-production gap that keeps GUI models stuck in the lab.
This is a systematic failure: models ground to visual primitives like shape, position, and color rather than functional semantics [17]. A white rectangle at the top of the screen represents “text input,” regardless of whether it is a search bar, a formula bar, or a URL field. The model has skewed representation of what the element might do.
Current evaluation datasets can't tell us how widespread the white rectangle problem is [1,3-12]. They evaluate on fixed scenes with fixed instructions: a specific screenshot, a referring expression, a single correct answer. That measures peak performance under curated conditions, not how models degrade when layout, zoom, or wording shift, which is much closer to production.
The question is whether we can measure grounding robustness systematically:
Instead of only measuring peak accuracy on a fixed scene, can we measure how models hold up as scenes and instructions vary?
In this technical report, we introduce GUI-Perturbed, a dataset built on domain randomization principles that varies visual scenes and instructions along controlled axes to expose fragile grounding. We describe the dataset, the perturbation methodology, and the design decisions behind it.
Fixed Scenes Hide Fragile Models
Existing computer-using agent (CUA) evaluation datasets share a common structure: a fixed screenshot, a fixed instruction, and a fixed ground-truth target. Benchmarks like OSWorld [3], ScreenSpot-v2 [5], ScreenSpot-Pro [6], and OSWorld-G [4] each contribute valuable coverage of specific scenarios and applications. But they all evaluate under the same assumption: that the test set’s visual scene and instruction distribution is representative of real world scenarios.
In production, this assumption breaks constantly. Websites ship new themes. Browser zoom levels vary across users. Dark mode inverts color relationships. Users describe the same element in different ways depending on context. A model that scores 90% on a fixed test set may score far lower once any of these variables shift.
What we need is evaluation data that varies these conditions systematically, so we can measure robustness, not only peak performance. For this we borrow a technique from robotics: domain randomization.
GUI Perturbation — Research Series
Sim-to-Real to Demo-to-Production
Domain randomization is a standard technique for bridging the gap between simulation and the real world [13]. During training, we randomize visual properties of the simulator (textures, lighting, object colors, camera angles) so the policy is forced to learn features that are invariant to surface-level variation. A robot that has seen a red cup, a blue cup, and a transparent cup in training is more likely to generalize to a cup it has never seen than one trained on a single appearance.
The benefits are well-established. Domain randomization forces invariance to irrelevant visual features [16]. It exposes failure modes that fixed test sets miss. And it scales to large numbers of scenarios without manual curation: you generate new training or evaluation data by sampling new random variations.
The parallel to GUI agents is direct. Models trained and evaluated on fixed screenshots are analogous to policies trained in a single simulator skin. They memorize the visual shortcuts of their training distribution (where elements tend to appear, what colors they tend to be, which shapes correlate with which functions) instead of learning the structural relationships between elements. When the skin changes, the policy breaks.
Robotics

GUI

Applying domain randomization to GUIs, however, is a different engineering problem. Robotic simulators provide programmatic control over every visual parameter: change a texture map, adjust a light source, swap out an object mesh [15]. GUI environments do not offer similar interface parameters. Changing the appearance of a desktop application typically requires application-specific integration, and most production software exposes limited visual controllability.
Our workaround is to operate on MHTML archives of real web pages. MHTML files capture a complete snapshot of a rendered web page, including HTML, CSS, images, and layout, in a single archive. They also preserve the DOM (Document Object Model) structure, which gives us programmatic access to the same elements a browser renders visually. We can add, remove, restyle, and reposition actual DOM elements rather than being limited to pixel-level image transforms.
Think of the MHTML file as our simulator. With it, we can randomize the visual environment while keeping the underlying page structure intact.
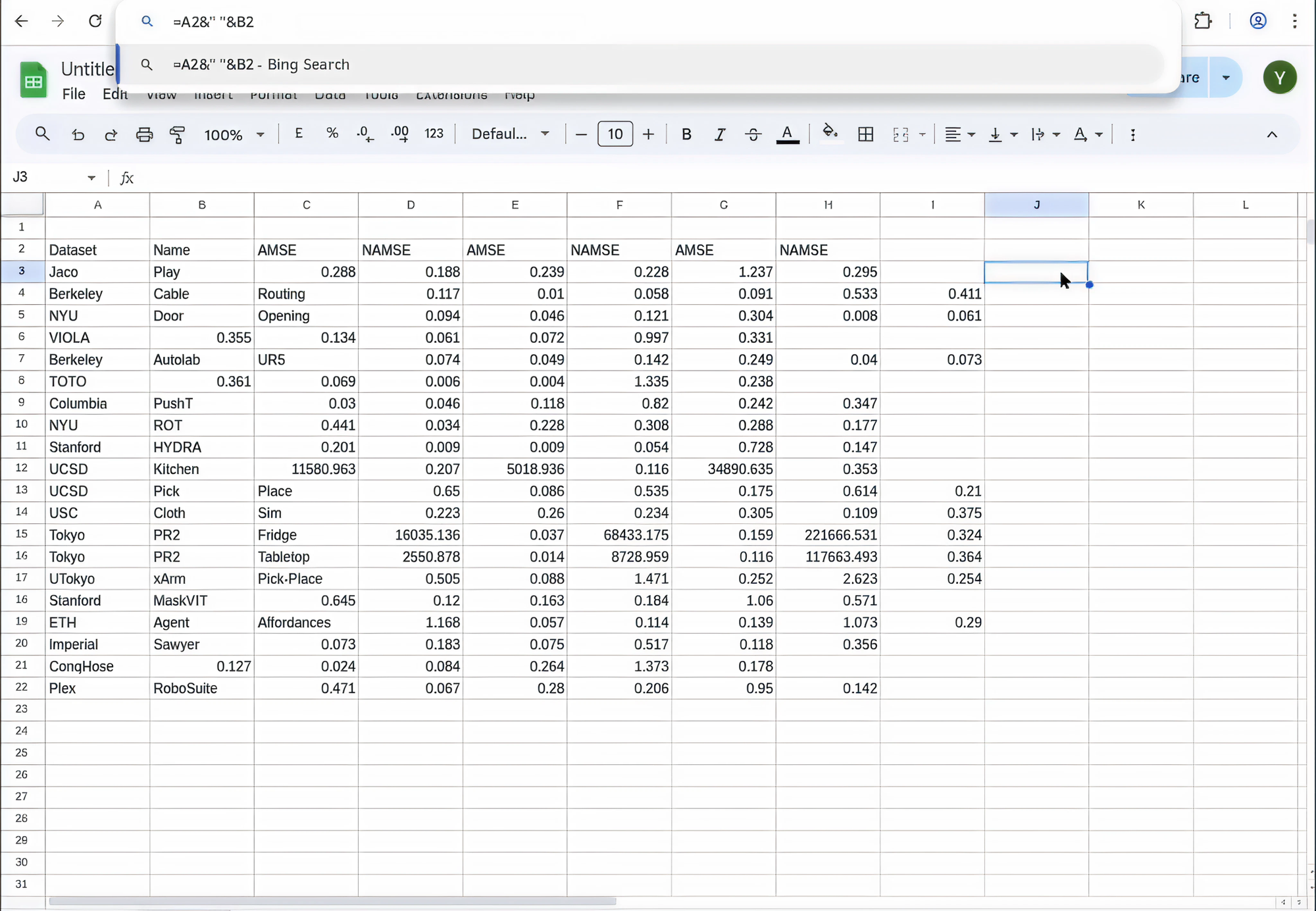
Building GUI-Perturbed
Building GUI-Perturbed comes down to three choices: which sub-problem to evaluate, what to use as a controllable simulator, and how to perturb it. We isolate step-level grounding, treat Mind2Web's MHTML archives as our simulator, and perturb along two axes: the visual scene and the instruction.
Isolating Step-Level Grounding
We focus on a single, well-defined sub-problem: given a screenshot and a natural language instruction referring to a specific GUI element, can the model correctly identify that element?
We deliberately exclude planning, navigation, and multi-step execution so we can attribute failures to grounding rather than upstream errors. If a model fails a multi-step task, it is hard to tell whether the failure came from misreading the instruction, locating the element, or choosing the action. By isolating grounding, we get clean signal.
In the language of our domain randomization analogy, this is single-move evaluation: grading each grounding decision independently, the way an analysis engine grades individual chess moves rather than judging by the outcome of the whole game.
Mind2Web as Our Simulation Engine
We build GUI-Perturbed on top of the Mind2Web dataset, which provides MHTML archives of real websites alongside annotated interaction traces [10]. Each MHTML file captures a complete web page that we can load, manipulate, and re-render.
This gives us a key advantage over screenshot-only approaches. With raw screenshots, perturbation options are limited to pixel-level operations: color shifts, crops, rotations, noise injection. With DOM access, we can make semantically meaningful changes: restyle a button, reposition a form field, swap the order of navigation items, change the theme of the entire page. These are the kinds of variations that occur naturally in production and that fixed-scene benchmarks miss.
Two Axes of Perturbation
A grounding model takes two inputs: a visual scene (the screenshot) and an instruction (the natural language description of the target element). We perturb both.
Figure 4: Two-axis perturbations: visual scene axis × instruction axis
Visual scene perturbations change the rendered page while preserving the target element. The goal is to alter the visual context (neighboring elements, page style, layout properties) so that a model relying on visual shortcuts will fail while a model with structural understanding will succeed.
Instruction perturbations change how the target element is described. The same button can be referred to as “the submit button,” “the green button at the bottom of the form,” or “the button below the email field.” Each phrasing requires different capabilities: keyword matching, visual attribute recognition, or spatial reasoning.
Returning to our domain randomization analogy: visual perturbations are like changing the simulator’s textures and lighting conditions. Instruction perturbations are like giving the robot a different way of specifying the goal. Grounding has to survive both.
Relational Instructions
Half of our instruction perturbations use relational instructions: referring expressions that identify the target element by its spatial or functional relationship to other elements on the page, rather than by the target’s own properties.
For example:
- “Click on ‘unread message’ above the ‘reservation email’”
- “Click on the arrow icon under the second image to expand the comments”
Compare these to direct instructions like “click the blue submit button” or “click the search icon.” Direct instructions require the model to match a description to a single element. Relational instructions require the model to identify a reference landmark, reason about a spatial relationship (above, below, next to, between), and then locate the target relative to that landmark.
We define relational instructions precisely: a relational instruction is one that identifies the target element for an action based on a given reference landmark and direction descriptions.
This distinction matters for two reasons. First, relational instructions reflect how humans actually refer to GUI elements in practice. When guiding someone through a UI over the phone, we say “click the button next to the search bar,” not “click the element at coordinates (450, 230).” Second, relational instructions interact with visual perturbations in diagnostic ways. If we move a neighboring element, does the model still resolve “next to the search bar” correctly? This creates a natural test of whether the model maintains a structured spatial representation of the page or relies on memorized co-occurrence patterns.
The term relational instruction carries across all three parts of this series: it is central to the evaluation results in Part 2 and the training experiments in Part 3.
Anatomy of a Perturbation
| Original Variant | Style Variant |
|---|---|
 |
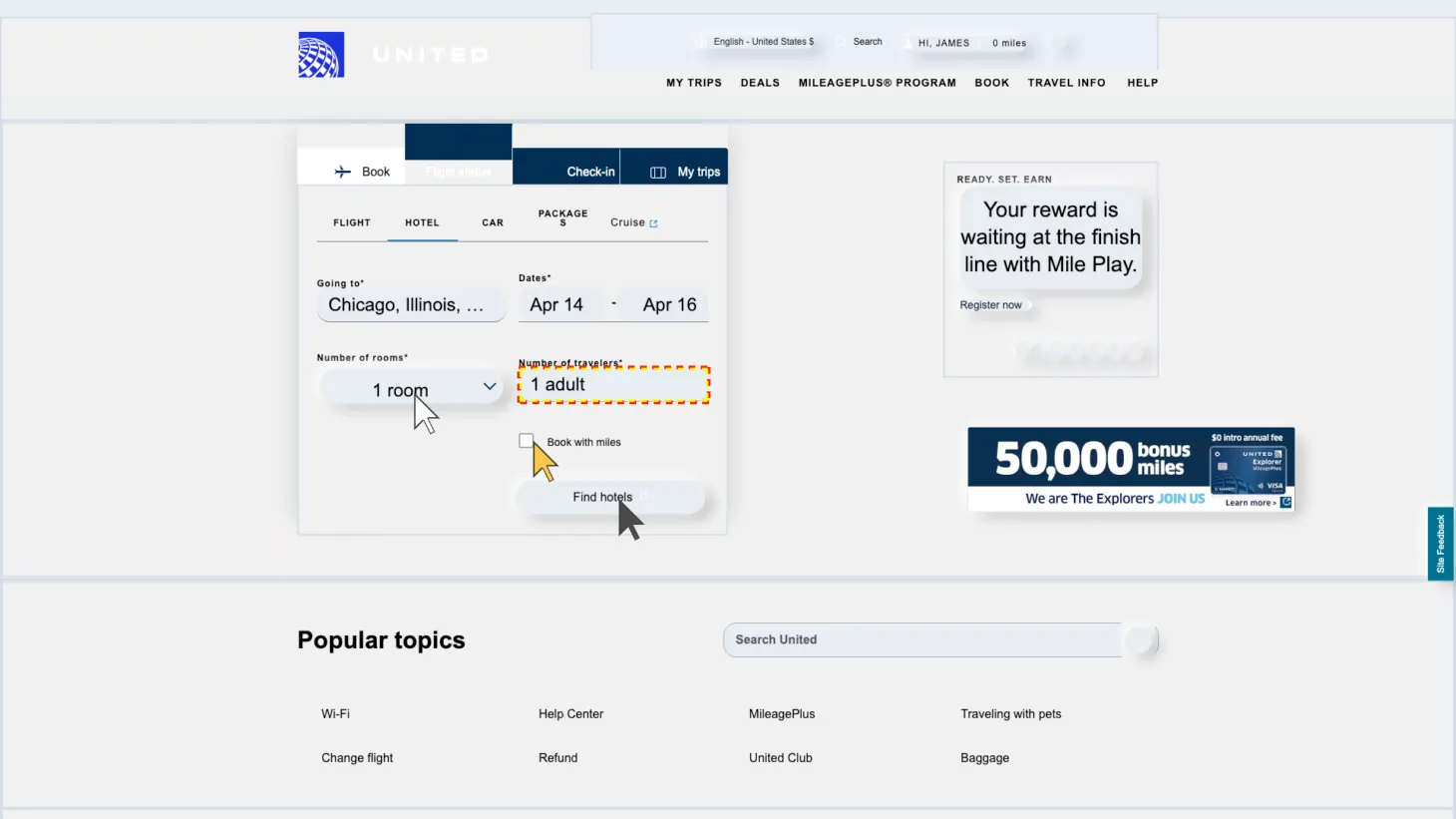 |
Figure 6: Original variant vs. style variant examples from GUI-Perturbed. Click on each image to enlarge.
The figure above shows an example directly from GUI-Perturbed. On the left is the original Mind2Web screenshot with its associated instruction. On the right is a perturbed version of the same page.
A robust grounding model should recognize that despite the visual changes, the target element still serves the same function and still satisfies the instruction. Each perturbation is designed so that a model relying on surface-level visual associations (element position, surrounding colors, layout proximity) should fail it, while a model that understands the element's functional role should succeed.
Dataset At A Glance
| Variant | N | Description |
|---|---|---|
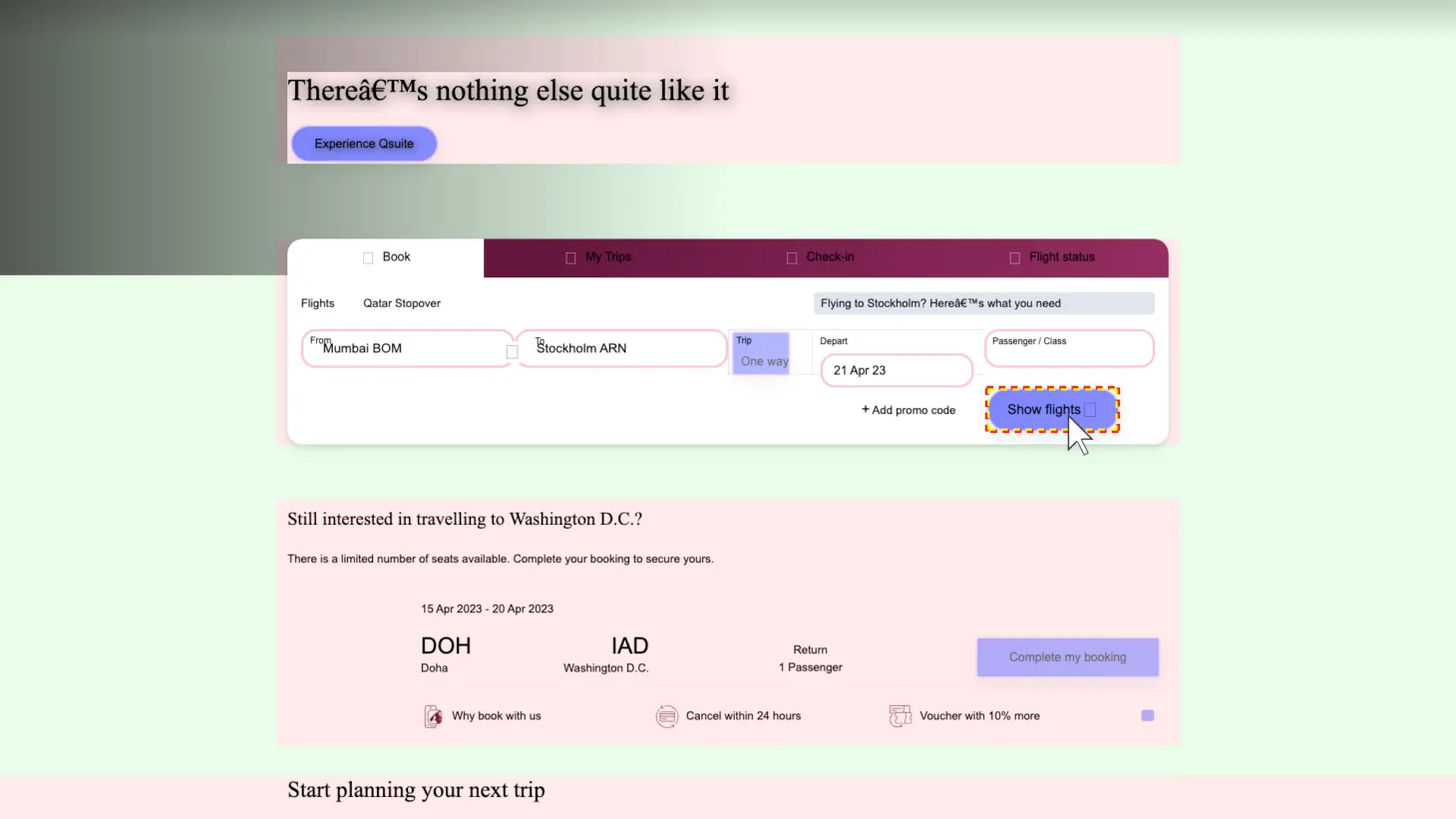
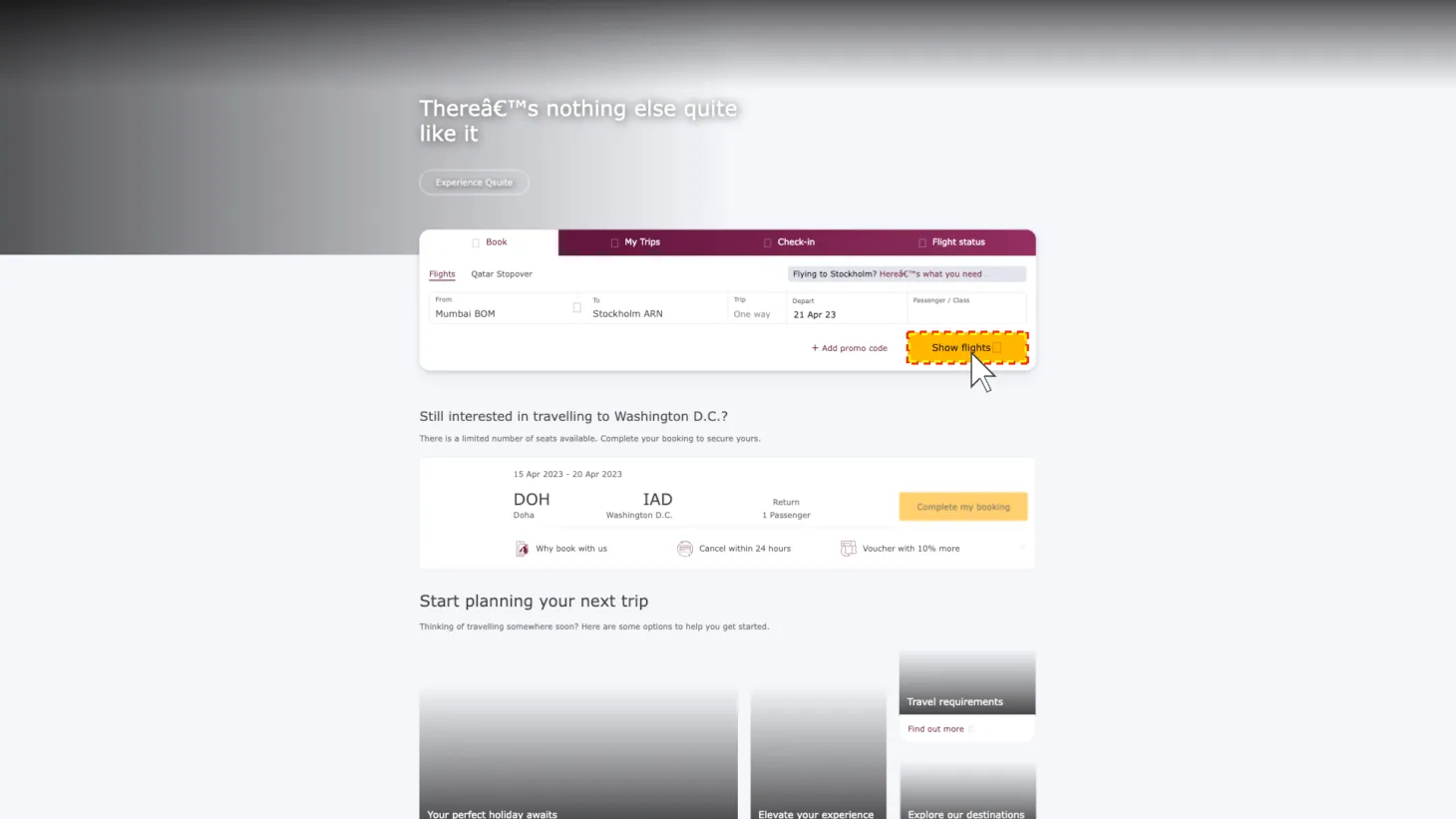
| Original | 390 | Obtained the screenshots of the pages directly rendered from Mind2web mhtml files (the original pages) |
| Style | 390 | Obtained the screenshots after injecting the original pages with templated CSS and JS code to randomize their button orders and element styles |
| Precision | 390 | Obtained the screenshots after scaling the pages to 0.7 |
| Text Shrink | 390 | Obtained the screenshots after scaling down the text font size |
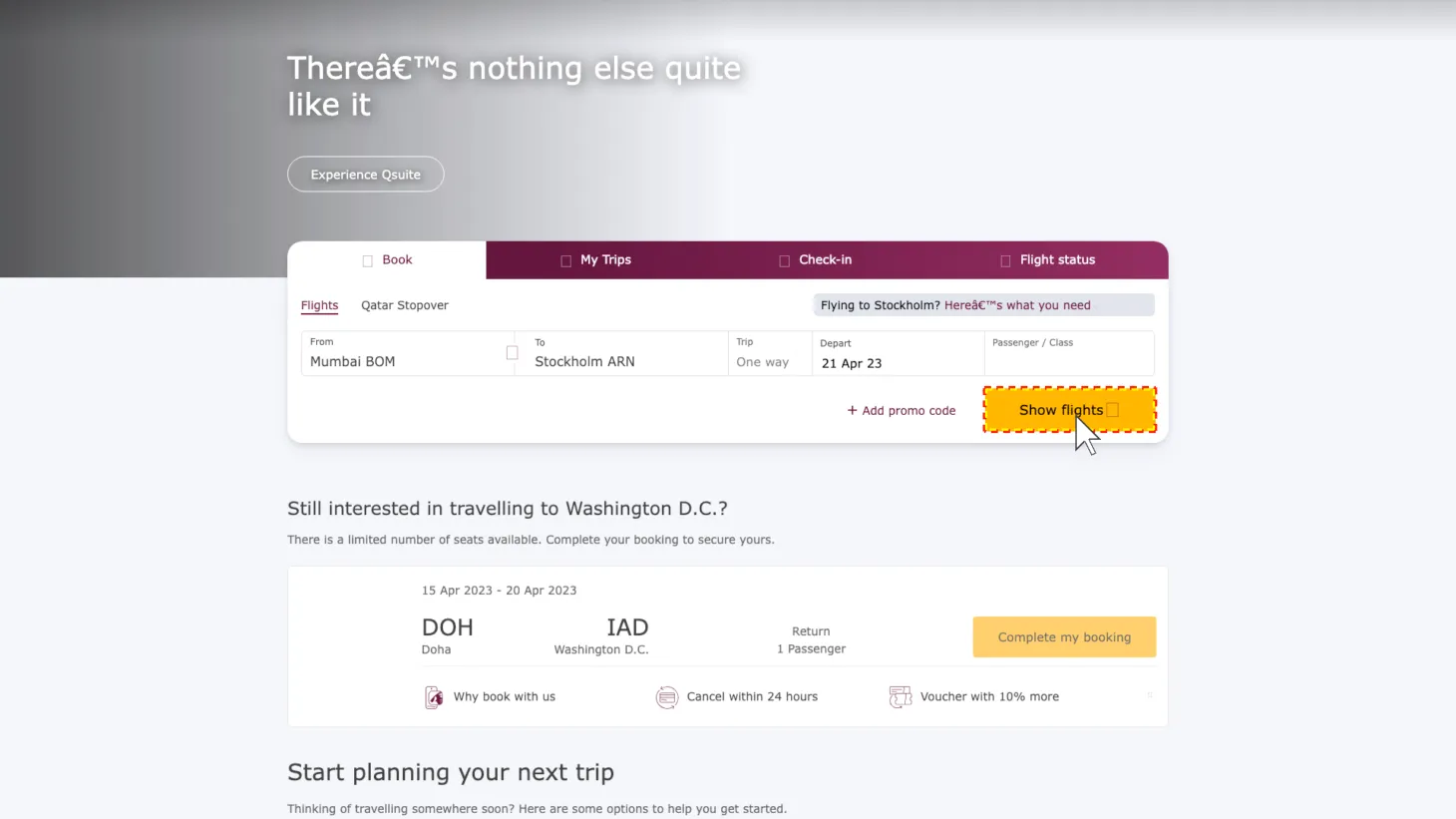
| Original | Style | Precision | Text Shrink |
|---|---|---|---|
 |
 |
 |
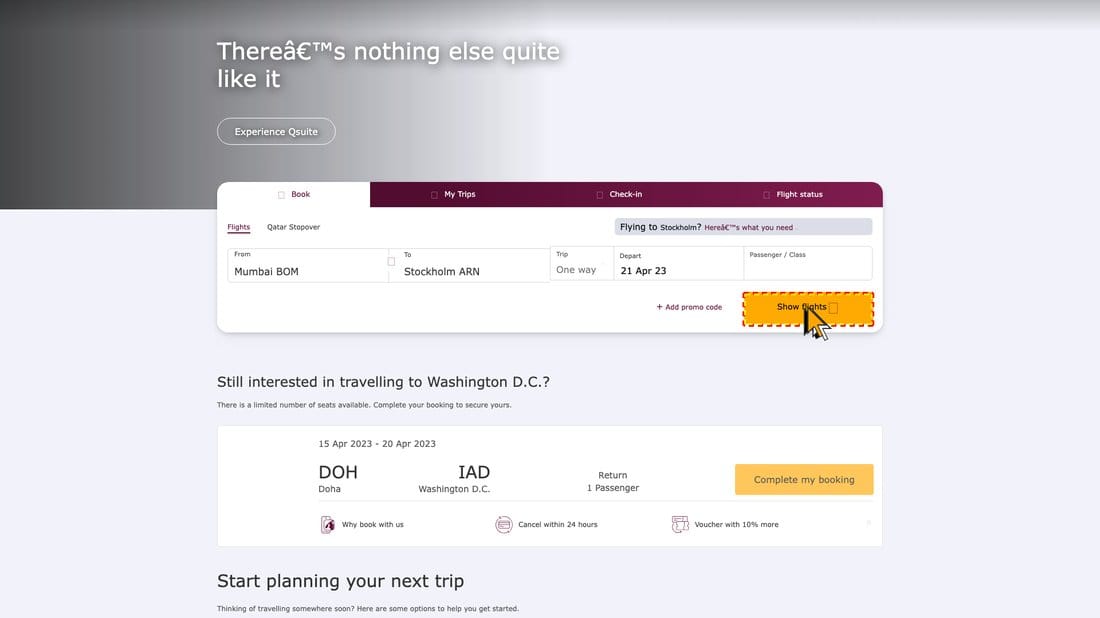 |
Figure 7: Perturbation Examples. Click on each image to enlarge.
Scope and Limitations
Perturbation realism. Not all perturbations produce pages that look like production websites. We prioritize diagnostic coverage over photo-realism. A perturbation that no real website would produce can still reveal a meaningful model weakness: if a model fails when we change the background color of a page, that failure tells us something about the model’s reliance on color as a grounding cue, regardless of whether the specific color is realistic.
Instruction diversity. People refer to GUI elements in many ways. Our instruction perturbations cover a useful subset of referring expressions but not the full distribution of natural language. Expanding this coverage, particularly for colloquial and ambiguous references, is a direction for future work.
Web domain only. This release covers web-based GUIs. Desktop applications, mobile interfaces, and cross-application workflows present different challenges and are out of scope for this release.
What’s Next
At Fig, we're building the control layer for AI: systems that perceive an environment, act in it reliably, and improve from the experience. Frontier models have largely solved perception. Agency is the open problem — acting dependably in real environments, recovering from mistakes, and compounding over time — and it will not come from scaling language models alone. Computer use is where we begin, and grounding is where the gap first surfaces: a model that can read a screen but cannot reliably act on it is not yet in control. GUI-Perturbed measures that gap precisely. Closing it, across software today and every environment over time, is the work ahead. Subscribe to our newsletter to follow our progress.
Aside from its practical use as a benchmark, building GUI-Perturbed pushed us toward deeper questions about grounding itself: how models represent interface elements, when they fall back on visual shortcuts instead of function, and how spatial and relational reasoning hold up as a scene changes. Domain randomization gives us a controlled lens on those questions and a way to measure progress rather than guess at it. We look forward to advancing this study, and to building the training recipes that turn these measurements into more reliable control.
We're advancing this work now, and will share two more updates in the coming days.
Part 2: Stress-Testing State-of-the-Art Models
In Part 2, we'll put GUI-Perturbed to work as a benchmark. We'll take three state-of-the-art CUA models that share a base checkpoint but differ in their post-training recipes, and ask a sharper question than aggregate accuracy allows: as the scene and the instruction shift along controlled axes, which grounding capabilities hold, and which quietly fall apart? The perturbation design will let us pinpoint exactly where, and reason about why.
Part 3: Can Fine-Tuning Close the Gap?
In Part 3, we'll ask whether the fragility can be trained away. We'll fine-tune on GUI-Perturbed data and trace how performance moves as we vary the recipe and scale the data up, to see whether more data is enough or whether closing the gap takes something different.
References
- T. Xue et al., "An Illusion of Progress? Assessing the Current State of Web Agents," Oct. 08, 2025, arXiv: arXiv:2504.01382. doi: 10.48550/arXiv.2504.01382.
- "Operator System Card." Accessed: Feb. 27, 2026. [Online].
- T. Xie et al., "OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments," May 30, 2024, arXiv: arXiv:2404.07972. doi: 10.48550/arXiv.2404.07972.
- T. Xie et al., "Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis," Oct. 24, 2025, arXiv: arXiv:2505.13227. doi: 10.48550/arXiv.2505.13227.
- K. Cheng et al., "SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents," Feb. 23, 2024, arXiv: arXiv:2401.10935. doi: 10.48550/arXiv.2401.10935.
- K. Li et al., "ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use," Apr. 04, 2025, arXiv: arXiv:2504.07981. doi: 10.48550/arXiv.2504.07981.
- B. Gou et al., "Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge," Jul. 03, 2025, arXiv: arXiv:2506.21506. doi: 10.48550/arXiv.2506.21506.
- J. Y. Koh et al., "VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks," Jun. 06, 2024, arXiv: arXiv:2401.13649. doi: 10.48550/arXiv.2401.13649.
- T. Shi, A. Karpathy, L. Fan, J. Hernandez, and P. Liang, "World of Bits: An Open-Domain Platform for Web-Based Agents," in Proceedings of the 34th International Conference on Machine Learning, PMLR, Jul. 2017, pp. 3135–3144.
- X. Deng et al., "Mind2Web: Towards a Generalist Agent for the Web," Dec. 09, 2023, arXiv: arXiv:2306.06070. doi: 10.48550/arXiv.2306.06070.
- J. Yang et al., "GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies," Jun. 17, 2025, arXiv: arXiv:2506.14477. doi: 10.48550/arXiv.2506.14477.
- H. H. Zhao, K. Yang, W. Yu, D. Gao, and M. Z. Shou, "WorldGUI: An Interactive Benchmark for Desktop GUI Automation from Any Starting Point," Feb. 22, 2026, arXiv: arXiv:2502.08047. doi: 10.48550/arXiv.2502.08047.
- T. Chen et al., "RoboTwin 2.0: A Scalable Data Generator and Benchmark with Strong Domain Randomization for Robust Bimanual Robotic Manipulation," Aug. 27, 2025, arXiv: arXiv:2506.18088. doi: 10.48550/arXiv.2506.18088.
- L. Weng, "Domain Randomization for Sim2Real Transfer." Accessed: Feb. 27, 2026. [Online].
- "Domain Randomization With Replicator — Getting Started With Isaac Sim." Accessed: Mar. 02, 2026. [Online].
- J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, "Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World," Mar. 20, 2017, arXiv: arXiv:1703.06907. doi: 10.48550/arXiv.1703.06907.
- K. Yu, N. Yu, H. Wang, R. Yang, and H. Zhang, "How do visual attributes influence web agents? A comprehensive evaluation of user interface design factors," Jan. 29, 2026, arXiv: arXiv:2601.21961. doi: 10.48550/arXiv.2601.21961.
Get Involved
At Fig, we believe reliable computer use requires models that understand why a GUI element serves a particular function, not just where it appears on screen. GUI-Perturbed is part of our broader work on control intelligence. You can reach out to us at contact@metarch.ai.
Citation
@online{gui_perturbed_technical_report_2026,
title = {GUI-Perturbed: A Domain Randomization Dataset for GUI Grounding},
author = {Yangyue Wang and Harshvardhan Sikka and Yash Mathur and Tony Zhou and Jinu Nyachhyon and Pranav Guruprasad},
year = {2026},
url = {www.fig.inc/blog/domain-randomization-for-computer-control/},
note = {Part 1: Dataset & methodology}
}
